반응형
| 서초종합체육관 | https://seochosc.com/pages/gallery2#none | |
| KBS 스포츠월드 | https://kbssw.co.kr/index.do | 수영,볼링 |
| 고양체육관 | https://gym.gys.or.kr:447/lecture/swim_guide.php | 수영,다이빙 |
반응형
| 서초종합체육관 | https://seochosc.com/pages/gallery2#none | |
| KBS 스포츠월드 | https://kbssw.co.kr/index.do | 수영,볼링 |
| 고양체육관 | https://gym.gys.or.kr:447/lecture/swim_guide.php | 수영,다이빙 |
가. 데이터의 정의
① 라틴어 dare(주다)의 과거 분사형으로 “주어진 것”이라는 의미
② 데이터는 추론과 추정의 근거를 이루는 사실이다.
③ 데이터는 단순한 객체로서의 가치뿐만 아니라 다른 객체와의 상호 관계 속에서 가치를 갖는다.
나. 데이터의 특성
① 존재적 특성
i. 객관적 사실
② 당위적 특성
i. 추론, 예측, 전망, 추정을 위한 근거
다. 수요 조사나 실험, 검사, 측정 등을 통해 데이터를 수집, 축적하고 다양한 방법으로 분석하여 간단한 마케팅 리포트로부터 심도 있는 논문, 미래 예측을 위한 경영 전략 또는 정책을 수립하는 일련의 가치 창출 과정에서 기초를 이루는 것을 데이터라고 한다.
라. 양질의 데이터를 확보하지 못하면 잘못된 분석 결과를 얻음
마. 창의적인 데이터 메시업(Mashup)은 기존에 풀기 어려운 문제 해결에 도움
바. 공공부문에서 개방하고 있는 데이터는 교통 데이터, 물가 데이터, 의료 데이터 이다
| 형태 | 정성적 데이터(qualitative data) | 정량적 데이터(quatitative data) |
| 형식 | 언어, 문자 | 수치,도형,기호 |
| 예 | 회사 매출이 증가함 | 나이,몸무게,주가 |
| 비정형 데이터 | 정형 데이터 | |
| 주관적 내용 | 객관적 내용 | |
| 통계 분석이 어려움 | 통계분석이 용이함 | |
| 데이터베이스 | 특정 스키마가 없는 NoSQL DB사용 | SQL 기반 관계형 DB사용 |
| 검색 | 구조화 되어있지 않아 찾기 어려움 | 쉽게 검색가능 |
| 저장위치 | 데이터 레이크 | 데이터 웨어하우스 |
| 유 형 | 내 용 | 예 시 |
| 정형 데이터 | - 형태(고정된 필드)가 있으며, 연산이 가능함. 주로 관계형 데이터 베이스(RDBMS)에 저장됨 - 데이터 수집 난이도가 낮고 형식이 정해져 있어 처리가 쉬운 편 |
관계형데이터베이스, 스프레드시트, CSV |
| 반정형 데이터 | - 데이터 내부에 메타 데이터를 갖고 있으며 일반적으로 파일 형태로 저장 - 형태(스키마, 메타데이터)가 있으며, 연산이 불가능. 주로 파일로 저장됨 메타데이터: l 데이터에 관한 구조화된 데이터로 다른 데이터를 설명해 주는 데이터 l 데이터에 대한 데이터로써 하위 레벨의 데이터를 설명/기술하려는 것 - 데이터 수집 난이도가 중간. 보통 API 형태로 제공되기 때문에 데이터 처리 기술(파싱)이 요구됨 |
XML, HTML, JSON XML (Extensible Markup Language) 다목적 마크업언어 (태그를 이용한 언어) 이다. 인터넷에 연결된 시스템끼리 데이터를 쉽게 주고 받을 수 있게 하여 HTML의 한계를 극복할 목적으로 만들어졌다 XML 기반 언어는 XHTML, SVG 등이 있다. |
| 비정형데이터 | - 형태가 없으며, 연산이 불가능. 주로 NoSQL 에 저장됨 - 데이터 수집 난이도가 높으며 텍스트 마이닝 혹은 파일일 경우 파일을 데이터 형태로 파싱해야 하기 떄문에 수집 데이터 처리가 어려움 - 데이터 내부에 메타 데이터를 갖고 있으며 일반적으로 파일 형태로 저장(X) |
소셜데이터, 영상, 이미지, 음성, 텍스트 |
가. 데이터는 지식 경영의 핵심 이슈인 암묵지와 형식지의 상호작용에 있어 중요한 역할을 한다.
나. 암묵지
① 의미: 학습과 경험을 통해 개인에게 체화되어 있지만 겉으로 드러나지 않는 지식
② 예: 김장 담그기, 자전거 타기
③ 특징: 사회적으로 중요하지만, 다른 사람에게 공유되기 어렵다
④ 상호작용: 공통화. 내면화
⑤ 개인에게 축적된 내면화된 지식-> 조직의 지식으로 공통화
다. 형식지
① 의미: 문서나 매뉴얼처럼 형상화된 지식
② 예: 교과서, 비디오, DB
③ 특징: 전달과 공유가 용이
④ 상호작용: 표출화, 연결화
⑤ 표출화: 개인에게 내재된 경험을 객관적인 데이터로 문서나 매체에 저장. 가공. 분석하는 과정
⑥ 언어, 기호, 숫자로 표출화된 지식 -> 개인의 지식으로 연결화
라. 암묵지와 형식지의 상호작용 관계: 공통화->표출화->연결화->내면화
가. DIKW의 정의
| 구 분 | 내 용 |
| 데이터(Data) | i. 개별 데이터 자체로는 의미가 중요하지 않은 객관적인 사실 ii. 존재 형식을 불문하고, 타 데이터와의 상관관계가 없는 가공하기 전의 순수한 수치나 기호를 의미 예) A마트는 100원에, B마트는 200원에 연필을 판매한다. |
| 정보(Information) | i. 데이터의 가공, 처리와 데이터간 연관관계 속에서 의미가 도출되는 것 ii. (정보)는 데이터의 가공 및 상관 관계간 이해를 통해 패턴을 인식하고 그 의미를 부여한 데이터 iii. 지난 1년 매출의 50%는 8월에 집중되어 있다 iv. 지난 1년 매출은 1월에서 8월까지 증가하였고, 12월까지 다시 증가하였다 v. 8월 A상품 구매 고객의 80%가 40대 여성 고객으로 대부분 회사원이다 예) A마트의 연필이 더 싸다. |
| 지식(Knowledge) | i. 데이터를 통해 도출된 다양한 정보를 구조화하여 유의미한 정보를 분류하고 개인적인 경험을 결합시켜 고유의 지식으로 내재화된 것 ii. 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물 iii. B 사이트보다 가격이 상대적으로 저렴한 A사이트에서 USB를 사야겠다. iv. 날씨가 따뜻해지고, 지점을 확장하여 올 8월 매출액은 3000만원으로 예상한다. 예) 상대적으로 저렴한 A마트에서 연필을 사야겠다. |
| 지혜(Wisdom) | i. 지식의 축적과 아이디어가 결합된 창의적인 산물 ii. 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적 아이디어 예) A마트의 다른 상품들도 B마트보다 쌀 것이라고 판단한다. |
나. DIKW 피라미드
① 데이터->정보->지식을 통해 최종적으로 지혜를 얻어내는 과정을 계층적으로 설명하고 있다.
② 개별 데이터 자체로는 의미가 중요하지 않은 객관적 사실에서 데이터를 가공 및 처리하여 정보, 지식, 지혜, 기호(X) 를 얻을 수 있다.
가. 1차 개념 확대: 정형 데이터 관리
① EU
체계적이거나 조직적으로 정리되고 전자식 또는 기타 수단으로 개별적으로 접근할 수 있는 독립된 저작물, 데이터 또는 기타 소재의 수집물
② 국내 저작권법
소재를 체계적으로 배열 또는 구성한 편집물로써 개별적으로 그 소재에 접근하거나 검색할 수 있도록 함
나. 2차 개념 확대
① 국내 컴퓨터 용어 사적
동시에 복수의 적용 업무를 지원할 수 있도록 복수 이용자 요구에 대응해서 데이터를 받아들이고 저장, 공급하기 위하여 일정한 구조에 따라 편성된 데이터의 집합
② 국내 Wikipedia
관련된 레코드의 집합, 소프트웨어로는 데이터베이스관리시스템(DBMS)를 의미
③ 국내 데이터분석 전문가 가이드
문자, 기호, 음성, 화상, 영상 등 상호 관련된 다수의 콘텐츠를 정보 처리 및 정보통신 기기에 의하여 체계적으로 수집 추적하여 다양한 용도와 방법으로 이용할 수 있도록 정리한 정보의 집합체
가. 데이터베이스의 일반적인 특징(암기 필요)
| 데이터베이스 특징 | 설 명 |
| 통합된 데이터 (Integrated data) |
동일한 내용의 데이터가 중복되어 있지 않는다는 의미 |
| 저장된 데이터 (stored data) |
자기 디스크나 자기 테이프 등과 같이 컴퓨터가 접근할 수 있는 저장 매체에 저장되는 것을 의미 |
| 공용 데이터 (shared data) |
여러 사용자가 서로 다른 목적으로 데이터를 공동으로 이용한다는 것을 의미 |
| 변화되는 데이터 (changable data) |
데이터베이스에 저장된 내용은 곧 데이터베이스의 현 시점에서의 상태를 의미, 새로운 데이터의 삽입, 갱신, 삭제로 항상 변화하여도 항상 현재의 정확한 데이터를 유지해야 함 |
| 인덱스 | i. 데이터베이스내의 데이터를 신속하게 정렬하고 탐색하게 해주는 구조 ii.데이터베이스의 테이블에서 고속의 검색동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공 |
나. 다양한 측면에서의 특징
① 정보 축적 및 전달 측면
② 정보 이용 측면
③ 정보 관리 측면
④ 정보기술 발전 측면
⑤ 경제 산업 측면
가. 1980년대 기업내부 데이터베이스
| OLTP | OLAP | |
| 약어 | On-Line Transaction Processing | On-Line Analytical Processing |
| 정의 | 여러 단말에서 보내온 메시지에 따라 호스트 컴퓨터가 데이터베이스를 엑세스하고 바로 처리 결과를 돌려보내는 형태 데이터 베이스를 수시로 갱신 |
다양한 비즈니스 관점에서 쉽고 빠르게 다차원적인 데이터에 접근하여 의사 결정에 활용할 수 있는 정보를 얻을 수 있게 해주는 기술 다차원의 데이터를 대화식으로 분석하기 위한 기술 |
| 데이터 구조 | 복잡 | 단순 |
| 데이터 갱신 | 동적으로 순간적 | 정적으로 주기적 |
| 응답시간 | 수 초 이내 | 수초에서 몇 분 사이 |
| 데이터 범위 | 수 십일 전후 | 오랜 기간 저장 |
| 데이터 성격 | 정규적인 핵심 데이터 | 비정규적인 읽기 전용 데이터 |
| 데이터 크기 | 수 기가 바이트 | 수 테라 바이트 |
| 데이터 내용 | 현재 데이터 | 요약된 데이터 |
| 데이터 특징 | 트랜젝션 중심 | 주제 중심 |
| 데이터 엑세스 빈도 | 높음 | 보통 |
| 질의 결과 예측 | 주기적이며 예측 가능 | 예측하기 어렵다 |
나.2000년대 기업내부 데이터베이스
① CRM(Customer Relationship Management, 고객 관계 관리)
i. 기업이 고객과 관련된 내/외부 자료를 분석 통합해 고객 중심 자원을 극대화하고, 이를 토대로 고객 특성에 맞게
마케팅 활동을 계획, 지원, 평가하는 과정
ii. 단순한 정보의 수집에서 탈피, 분석 중심의 시스템 구축 지향
iii.기업의 내부 고객들만을 대상으로 한 정보시스템(X)
② SCM(Supply Chain Management, 공급망 관리)
i.기업에서 원재로의 생산, 유통 등 모든 공급망 단계를 최적화해 수요자가 원하는 제품을 원하는 시간과 장소에 제공하는 것
ii.(SCM)은 기업이 외부 공급업체 또는 제휴업체와 통합된 정보시스템으로 연계하여 시간과 비용을 최적화시키기 위한
것으로, 자재 구매, 생산, 재고, 유통, 판매, 고객 데이터로 구성된다.
다. 각 분야별 내부 데이터베이스
①분야별 데이터베이스 개념
②분야별 데이터베이스 소개
| 분야 | 내용 |
| 제조부문 | l 클라이언트/서버 기반의 내부 정보시스템이 웹기반의 데이터베이스로 전환되고 있다. ERP (Enterprise Resource Planning) -인사, 재무, 생산 등 기업의 전 부문에 걸쳐 독립적으로 운영되던 각종 관리 시스템의 경영자원을 하나의 통합시스템으로 재구축함으로써 생산성을 극대화하려는 경영혁신기법 -기업 전체의 경영자원의 효과적 이용이라는 관점에서 통합적으로 관리하고 경영의 효율화를 기하기 위한 시스템 BI (Business Intelligence) - 의사결정에 활용하는 일련의 프로세스 - 데이터 기반 의사결정을 지원하기 위한 리포트 중심의 도구 CRM (Customer Relationship Management) - 고객 중심 자원을 극대화 RTE (Real-Time Enterprise) - 회사의 주요 경영정보를 통합관리하는 실시간 기업의 새로운 기업경영시스템이다. - 회사 전부문의 정보를 하나로 통합함으로써 경영자의 빠른 의사 결정을 이끌어 내려는 목적 Business Analytics - 의사 결정을 위한 통계적이고 수학적인 분석에 초점을 둔 기법 |
| 금융부문 | l 업무 프로세스 효율화나 통합시스템 구축으로 확산되고 있다. EAI (Enterprise Application Integration) - 정보를 중앙 집중적으로 통합, 관리, 사용할 수 있는 환경 구현 EDW (Enterprise Data Warehouse) - DW (Data Warehouse)를 전사적으로 확장한 모델로 BPR과 CRM, BSC 같은 다양한 분석 애플리케이션을 위한 원천이 된다. |
| 유통부문 | KMS (Knowledge Management System) - 지식관리시스템 - 조직 내 구성원들이 축적하고 있는 노하우 등 암묵적 지식을 형식지로 표출화 될 수 있도록 지원하는 등, 조직의 경쟁력향상을 위해 지식자원을 체계화하고 원활하게 공유가 될 수 있도록 지원하는 시스템 RFID (RF, Radio Frequency) - 주파수를 이용해 ID를 식별하는 system |
라.사회 기반구조로서의 데이터베이스
① 개념
i. 사회 각 부분의 정보화가 본격화되면서 데이터베이스 구축이 활발하게 추진되었다.
② 종류
i. EDI (Electric Date Interchange)
l 각종 서류를 표준화된 양식을 통해 전송
ii. VAN(Value Added Network, 부가가치통신망)
l 공중 전기통신사업자로부터 통신회선을 차용하여 독자적인 네트워크를 형성하는 것
iii. CALS (Commerce at Light Speed)
l 전자상거래 구축을 위해 기업 내에서 비용 절감과 생산성 향상을 추구할 목적으로 시작된, 제품의 설계, 개발, 생산에서 유통, 패기에 이르기 까지 제품의 라이프 사이클 전반에 관련된 데이터를 통합하고 공유, 교환할 수 있도록 한 경영 통합 정보 시스템
③ 분야별 사회 기반 구조의 데이터베이스
i. 물류 부문
l CVO (Commercial Vehicle Operation System, 화물 운송 정보)
l PORT-MISI (항만 운영 정보 시스템)
l KROIS (철도 운영 정보 시스템)
ii. 지리/교통부문
l GISI (Geographic Information System 지리정보시스템)
l RS (Remote Sensing, 원격탐사)
l GPS (global Positioning System)
l ITS (Intelligent Transport System 지능형 교통시스템)
l LBS (Location Based Service 위치기반서비스)
l SIM (Spatial Information Management 공간정보관리)
iii. 의료 부문
l PACS (Picture Archiving and Communication System)
l U헬스 (Ubiquitous Health)
iv. 교육 부문
l NEIS (National Education Information System, 교육행정정보시스템)
가. 빅데이터의 정의
① 빅데이터를 보는 관점에 따른 정의
i. 첫째, 3V로 요약되는 데이터 자체의 특성 변화에 초점을 맞춘 좁은 범위의 정의
ii. 둘째, 데이터 자체뿐만 아니라 처리, 분석 기술적 변화까지 포함되는 중간 범위의 정의
iii. 셋째, 인재, 조직 변화까지 포함한 넓은 관점에서의 빅데이터에 대한 정의
② 3V
i. Volume(양): 데이터의 규모 측면, 센싱데이터/비정형데이터
ii. Variety(다양성): 데이터 유형과 소스 측면, 정형/ 비정형데이터(영상, 사진)
iii. Velocity(속도): 데이터 수집과 처리 측면
③ 4V
i. Value (가치)
ii. Visualization (시각화)
iii. Veracity (정확성)
④ 빅데이터의 수집, 구축, 분석의 최종 목적은 새로운 통찰과 가치를 창출이다
⑤ 빅데이터는 일반적인 데이터베이스 소프트웨어로 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터다
⑥ 빅데이터는 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고 데이터의 초고속 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처이다
⑦ 빅데이터는 데이터 양(Volume), 데이터 유형과 소스 측면의 다양성(Variety), 데이터 처리 측면에서 속도(Velocity)가 급격히 증가하면서 나타난 현상이다.
⑧ 빅데이터는 기존의 작은 데이터 처리분석으로 얻을 수 없었던 통찰과 가치를 하둡(Hadoop)을 기반으로 하는 대용량의 분산처리 기술을 통해 창출하는 방식이다(X)
나. 빅데이터 정의의 범주 및 효과
① 데이터 변화
i. 규모, 형태, 속도
② 기술 변화:
i. 데이터 처리, 저장, 분석, 기술 및 아키텍처
ii. 클라우드 컴퓨팅 활용
③ 인재, 조직 변화
i. Data Scientist 같은 새로운 인재 필요
ii. 데이터 중심 조직
가. 빅데이터 출현 배경
① 3가지 출현 배경
i. 산업계: 고객 데이터 축적
ii. 학계: 거대 데이터 활용, 과학 확산
iii. 기술발전: 관련 기술의 발달
② ICT의 발전과 빅데이터의 출현
③ 고객데이터의 축적과 거대 데이터의 활용이 늘어남으로 필요한 기술 아키텍처 및 통계도구들의 발전, 모바일 혁명 등의 관련 기술의 발달을 들 수 있다.
④ M2M, IOT와 같은 통신 기술의 발전
⑤ 하둡등 분산처리 기술의 발전
⑥ 트위터, 페이스북 등 SNS의 급격한 확산
⑦ 의료정보 등 공공 데이터 개방 가속화(X)
가. 빅데이터에 거는 기대를 표현한 비유
① 산업혁명의 석탄, 철
② 21세기의 원유
③ 렌즈
④ 플랫폼
i. 빅데이터의 기능으로 ‘공동 활용의 목적으로 구축된 유,무형의 구조물 역할을 수행한다’
ii. 빅데이터가 다양한 서드 파티 비즈니스에 활용되면서 플랫폼 역할을 할 것으로 전망된다.
iii. 페이스북은 2006년 F8 행사를 기점으로 자신들의 소셜그래프 자산을 외부 개발자들에게 공개하고 서드파티 개발자들이 페이스북 위에서 작동하는 앱을 만들기 시작하면서 (플랫폼) 역할을 하기 시작했다
iv. 하둡은 대규모 분산 병렬 처리의 업계 표준으로 맵리듀스 시스템과 분산 파일 시스템인 HDFS로 구성된 (플랫폼) 기술이며, 선형적인 성능과 용량 확장성, 고장 감내성을 가지고 있다.
v. 아마존은 S3, BC2 환경을 제공함으로써 (플랫폼)을 우한 클라우드 서비스를 최초로 실현하였다
가. 과거에서 현재로의 변화
① 사전 처리 -> 사후 처리
② 표본 조사 -> 전수 조사
③ 질 -> 양
④ 인과관계 -> 상관관계
i. 상관 관계를 통해 특정 현상의 발생 가능성이 포착되고, 그에 상응하는 행동을 하도록 추천되는 일이 점점 늘어나고 있다. 이처럼 데이터 기반의 상관 관계 분석 주는 인사이트가 인과 관계에 의한 미래 예측을 점점 압도해 가는 시대가 도래하게 될 것으로 전망된다.
나. 빅데이터가 만들어내는 변화
① 가치가 있을 것이라고 예상되는 특정한 정보만 모아서 처리하는 것이 아니라, 가능한 많은 데이터를 모으고 그 데이터를 다양한 방식으로 조합해 숨은 정보를 찾아내는 방식이 중요해 진다.
② 데이터의 규모가 증가함에 따라 사소한 몇 개의 오류 데이터는 분석결과에 영향을 미치지 않기 때문에 데이터세트에 포함하여 분석해도 상관없는 경우가 많아진다.
③ 인과관계의 규명없이 상관관계 분석 결과만으로 인사이트를 얻고 이를 바탕으로 수익을 창출할 수 있는 기회가 점차 늘어나고 있다.
④ 빅데이터의 등장으로 데이터 수집비용의 감소와 클라우드 컴퓨팅 기술의 발전으로 데이터 처리비용이 감소하게 되었다. 이로 인해 표본을 조사하는 기존의 지식 발견 방식에서 전수조사를 통해 샘플링이 주지 못하는 패턴이나 정보를 발견하는 방식으로 데이터 활용 방법이 변화되었다.
⑤ 데이터의 양이 증가하고 유형이 복잡해짐에 따라 수많은 데이터 중에서 분석에 필요한 데이터를 선정하기 위해 정교한 표본조사 기법의 중요성이 대두되고 있다(X)
가. 빅데이터의 가치 산정이 어려운 이유
① 데이터 활용 방식
i. 데이터 활용 방식에서는 재사용이나 재조합, 다목적용 데이터 개발등이 일반화되면서 특정 데이터를 언제 어디서 누가 활용할 지 알 수 없게 되었다. 따라서 가치를 산정하는 것도 어려워졌다
② 새로운 가치 창출
i. 기존에 없던 가치를 창출함에 따라 그 가치를 측정하기 어렵다
③ 분석 기술 발전
i. 현재는 가치가 없는 데이터일지라도, 추후에 새로운 분석 기법이 등장한다면 거대한 가치를 지닌 데이터가 될 수 있다.
④ 빅데이터 전문 인력의 증가로 다양한 곳에서 빅데이터가 활용되고 있기 때문이다.(X)
나. 빅데이터의 영향
① 다양한 시장 주체들이 빅데이터를 활용함에 따라 소비자이면서 국민인 일반인들은 맞춤형 서비스를 저렴한 비용으로 이용하게 되고, 적시에 필요한 정보를 얻음으로써 다양한 형태로 기회 비용을 절약할 수 있어 사람들이 점점 스마트해지고 있다.
② 기업: 혁신, 경쟁력 제고, 생산성 향상
③ 정부: 환경 탐색, 상황 분석, 미래 대응
④ 개인: 목적에 따른 활용
가. 기업
① 구글
i. 실시간 자동 번역 시스템,
ii. 사용자의 로그 데이터를 활용한 검색엔진 개발
② 넷플릭스
i. Cinematch시스템, 이용자의 콘텐츠 기호 파악하여 새로운 영화 추천
③ 라쿠텐 (X)
i. Cinematch시스템, 이용자의 콘텐츠 기호 파악하여 새로운 영화 추천
④ 월마트
i. 소셜 미디어를 통해 고객 소비패턴 분석하는 월마드랩(Wallmart Labs) 운영
ii. 고객의 구매 패턴을 분석해 상품 진열에 활용
⑤ 자라
i. 일일 판매량을 실시간 테이터 분석으로 상품 수요를 예측
나. 정부
① 정부는 실시간 교통 정보 수집, 기후 정보, 각종 지질 활동, 소방 서비스 등 다양한 국가 안전 확보 활동을 위해 실시간 모니터링을 활용하고 있다.
② 미래 의제인 의료와 교육 개선을 위해 빅데이터를 활용해 해결책을 모색한다
다. 개인
① 정치인은 선거 승리를 위해 사회관계망 분석을 통해 유세 지역을 선정하고, 해당 지역의 유권자에게 영향을 줄 수 있는 내용을 선정에 효과적인 선거 활동을 펼친다.
② 가수는 팬들의 음악 청취 기록 분석을 통해 실제 공연에서 부를 노래 순서를 짜는데 활용한다.
라. 신용평가는 투자자 보호를 위하여 금융상품 및 신용공여 등에 대하여 그 원리금이 상환될 가능성과 기업 법인 및 간접투자기구등의 신용도를 평가하는 행위이며 핀테크 분야에서 빅데이터 활용이 활발하게 이루어지고 있다.
가. 빅데이터 기본 테크닉
① 연관 규칙 학습
i. 변인들 간에 주목할 만한 상관관계가 있는지 찾아내는 방법
ii. 맥주를 사는 사람은 콜라도 같이 구매하는 경우가 많은가?
iii. A 마트는 금요일 저녁에 맥주를 사는 사람은 기저귀도 함께 구매했다는 사실을 발견하고 두 가지 상품을 가까운 곳에 진열하기로 결정했다.
② 유형 분석
i. 문서를 분류하거나 조직을 그룹으로 나눌 때, 또는 온라인 수강생들을 특성에 따라 분류할 때 사용
ii. 사용자가 어떤 특성을 가진 집단에 속하는지 알고자 할 때 사용
iii. 택배 차량을 어떻게 배차하는 것이 효율적인가? (X)
③ 유전자 알고리즘
i. 최적화가 필요한 문제의 해결책을 자연 선택, 돌연 변이 등과 같은 메커니즘을 통해 점진적을 진화시켜 나가는 방법
ii. (유전자 알고리즘)은 생명의 진화를 모방하여 최적해(Optimal Solution)을 구하는 알고리즘으로 존 홀랜드(John Holland)가 1975년에 개발하였다
iii. (유전자 알고리즘)은 ‘최대의 시청률을 얻으려면 어떤 시간대에 방송해야 하는가?’ 와 같은 문제를 해결할 떄 사용된다
iv. (유전자 알고리즘)은 어떤 미지의 함수 Y=f(x)를 최적화하는 해 x를 찾기 위해, 진화를 모방한 (Simulated evolution) 탐색 알고리즘이라고 할 수 있다.
④ 기계 학습
i. 훈련 데이터로부터 학습한 알려진 특성을 활용해 예측하는 방법
⑤ 회귀 분석
i. 독립 변수를 조직함에 따라 종속 변수가 어떻게 변하는지를 보면서 두 변인의 관계를 파악할 때 사용
ii. 고객의 만족도가 충성도에 어떤 영향을 미치는가?
⑥ 감정 분석
i. 특정 주제에 대해 말하거나 글을 쓴 사람의 감정을 분석
⑦ 감성 분석
i. 특정 주제에 대한 사용자의 긍정,부정 의견을 분석한다
ii. 주로 온라인 쇼핑몰에서 사용자의 상품명에 대한 분석이 대표적 사례이다
iii. 사용자가 사용한 문장이나 단어가 분석 대상이 된다
iv. 사용자간의 쇼셜 관계를 알아내고자 할 때 이용한다(X)
⑧ 소셜 네트워크 분석
i. 특정인과 다른 사람이 몇 촌 정도의 관계인가를 파악할 때 사용하고 영향력 있는 사람을 찾아낼 때 사용
ii. 사용자간의 쇼셜 관계를 알아내고자 할 때 이용한다
iii. 친분관계가 승진에 어떤 영향을 미치는가?
3. 플랫폼 비즈니스 모델
가. 상품, 서비스, 기술 등의 기반 위에 다른 이해관계자들이 보완적이 상품, 서비스, 기술을 제공하는 생태계 구축을 목표로 하는 비즈니스 모델
가. 사생활 침해
① 개인정보가 포함된 데이터를 목적 외에 활용할 경우 사생활 침해를 넘어 사회, 경제적 위협으로 변형 될 수 있다.
나. 책임 원칙 훼손
① 빅데이터 기본 분석과 예측 기술이 발전하면서 정확도가 증가한 만큼, 분석 대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성도 증가한다.
② 민주주의 국가에서는 잠재적 위협이 아닌 명확한 결과에 대한 책임을 묻고 있어 이에 따른 원리를 훼손할 가능성이 있다.
다. 데이터 오용
① 빅데이터는 일어난 일에 대한 데이터에 의존하기 때문에 이를 바탕으로 미래를 예측하는 것은 적지 않은 정확도를 가질 수 있지만 항상 맞을 수는 없다. 또한 잘못된 지표를 사용하는 것도 빅데이터의 피해가 될 수 있다.
가. 동의에서 책임으로
① 빅데이터에 의한 사생활 침해 문제를 해결하기에는 부족한 측면이 많고, 매번 개인정보 제공 동의를 하는 비효율적인 단계를 줄이고자 개인정보를 사용하는 사용자의 책임으로 해결하는 방안을 제시하였다
② 사생활 침해 문제를 해결 방안 -> 개인정보 제공 동의에서 정보 사용자 책임제로 변환
나. 결과 기반 책임 원칙 고수
① 책임 원칙 훼손 위기 요인에 대한 통제 방안으로 기존의 원칙을 좀 더 보강하고 강화할 필요가 있으며, 예측 자료에 의한 불이익을 당할 가능성을 최소화하는 장치를 마련하는 것이 필요하다
② 책임 원칙 훼손 위기 요인에 대한 통제 방안 -> 결과 기반 책임 원칙 고수
다. 알고리즘 접근 허용
① 데이터 오용의 위기 요소에 대한 대응책으로 ‘알고리즘에 대한 접근권’을 제공하여 예측 알고리즘의 부당함을 반증할 수 있는 방법을 공개할 것을 주문한다.
② 데이터 오용의 위기 요소에 대한 대응책 -> 알고리즘 접근 허용
라. 빅데이터가 발생시키는 문제를 중간자 입장에서 중재하며 해결해 주는 알고리즈미스트도 새로운 직업으로 부상하게 될 것이다.
가. 기본 3요소
① 데이터
모든 것을 데이터화하는 현 추세로 특정 목적없이 축적된 데이터를 통한 창의적인 분석이 가능해져 새로운 가치로 부상하고 있다.
② 기술
대용량의 데이터를 빠르게 처리하기 위한 알고리즘의 진화와 함께 스스로 학습하고 데이터를 처리할 수 있는 인공지능 기술이 출현하였다.
③ 인력
빅데이터를 처리하기 위한 데이터 사이언티스트와 알고리즈미스트의 역할을 통해 다각적 분석을 통한 인사이트 도출이 중요해지고 있다.
빅데이터의 열풍을 일종의 거품 현상으로 보는 회의론으로 인해 빅데이터 분석에서 찾을 수 있는 수많은 가치를 제대로 발굴해 보기도 전에 그 활용 자체를 사전에 차단해 버릴 수 있다.
가. 투자효과를 거두지 못했던 학습효과 -> 과거의 고객관계관리(CRM)
① 도입만하면 모든 문제를 한번에 해소할 것처럼 강조되었지만, 어떻게 활용하고 어떻게 가치를 뽑아내야 할지 난감해 함
나. 빅데이터 성공사례가 기존 분석 프로젝트를 포함해 놓은 것이 많다.
다. 데이터에서 가치, 즉 통찰을 이끌어내 성과를 창출하는 것이 관건이며, 분석을 통해 가치를 만드는 것에 집중해야 한다.
가. 빅데이터에 대한 관심 증대
데이터 기반의 통찰의 중요성에 대한 공감대 상승과 동시에 긍정적 효과를 기대한다
나. 빅데이터 프로젝트에 거는 기대
기존 프로세스의 자동화를 우선 시행한 후 점차적으로 거시적이고, 전략적인 가치를 이끌어 낼 수 있는 것으로 기대한다.
다. 빅데이터 분석의 가치
① 데이터는 크기의 이슈가 아니라, 거기에서 어떤 시각과 통찰을 얻을 수 있느냐의 문제가 중요하다
② 전략과 비즈니스의 핵심 가치에 집중하고 이와 관련된 분석 평가지표를 개발하고 이를 통해 효과적으로 시장과 고객 변화에 대응할 수 있을 때 빅데이터 분석은 가치를 줄 수 있다.
가. 단순히 분석을 많이 하는 것이 곧바로 경쟁우위를 가져다 주지는 않는다.
나. 전략적인 통찰력을 가지고 분석하고 핵심적인 비즈니스 이슈에 집중하여 데이터를 분석하고 차별적인 전략으로 기업을 운영해야 한다.
가. 산업별 분석 애플리케이션
① 금융서비스: 신용점수 산정, 사기 탐지, 가격 책정, 프로그램 트레이딩, 클레임 분석
② 병원: 가격 책정, 고객 로열티, 수익 관리
③ 에너지: 트레이딩, 공급/수요 예측
④ 정부: 사기 탐지, 사례관리, 범죄 방지, 수익 최적화
나. 일차적인 분석의 문제점
① 일차적인 분석을 통해서도 해당 부서나 업무 영역에서는 상당한 효과를 얻을 수 있지만 일차적인 분석만으로는 환경변화와 같은 큰 변화에 제대로 대응하거나 고객 환경의 변화를 파악하고 새로운 기회를 포착하기 어렵다
다. 전략 도출 가치 기반 분석
① 전략적인 통찰력을 창출에 포커스를 뒀을 때, 분석은 해당 사업에 중요한 기회를 발굴하고, 주요 경영진의 지원을 얻어낼 수 있으며 이를 통해 강력한 모멘텀을 만들어 낼 수 있다.
② 활용 범위를 더 넓고 전략적으로 변화시켜야 한다.
③ 사업성과를 견인하는 요소들과 차별화를 꾀할 기회에 대해 전략적 인사이트를 주는 가치기반 분석단계로 나아가야 한다.
가. 의미
① 데이터 공학, 수학, 통계학, 컴퓨터 공학, 시각화, 헤커의 사고방식, 해당분야의 전문지식을 종합한 학문이다.
② 데이터로부터 의미 있는 정보를 추출해내는 학문
나. 역할
① 비즈니스의 성과를 좌우하는 핵심이슈에 답을 하고, 사업의 성과를 견인
② 소통력이 필요
가. 데이터 사이언스의 영역
① 분석적 영역: Analytics
② 데이터 처리와 관련된 IT 영역:
i. 데이터 웨어하우징
ii. 분산 컴퓨팅
iii. 파이썬 프로그래밍
iv. 데이터 시각화(X)
③ 비즈니스 컨설팅 영역:
i. 비즈니스 분석
ii. 데이터 시각화
나. 데이터 사이언스의 역할
① 데이터 홍수 속에서 헤엄을 치고, 데이터 소스를 찾고, 복잡한 대용량 데이터를 구조화, 불완전한 데이터를 서로 연결해야 한다.
② 데이터 사이언티스트가 갖춰야 할 역량의 한가지는 “강력한 호기심” 이다.
③ 데이터 사이언티스트는 스토리텔링, 커뮤니케이션, 창의력, 열정, 직관력, 비판적 시각, 글쓰기능력, 대화능력을 갖춰야 한다.
가. Hard Skill
① 빅데이터에 대한 이론적 지식
② 분석 기술에 대한 숙련
나. Soft Skill
① 통찰력 있는 분석
② 설득력 있는 스토리텔링 능력
③ 다분야 간 커뮤니케이션 능력
④ 뉴럴네트워크 최적화 능력(X)
⑤ 알고리즘에 의해 부당하게 피해를 입은 사람을 구제하는 능력(X, 알고리즈미스트)
다. 데이터 사이언티스트가 갖춰야할 역량은 빅데이터의 처리 및 분석에 필요한 이론적 지식과 기술적 숙련에 관련된 능력인 (Hard) Skill 과 데이터 속에 숨겨진 가치를 발견하고 새로운 발전 기회를 만들어 내기 위한 능력인 (Soft) Skill 로 나뉘어진다
분석기술보다 중요한 것은 소프트 스킬로 전략적 통찰을 주는 분석은 단순 통계나 데이터 처리와 관련된 지식 외에도 스토리텔링, 커뮤니케이션, 창의력, 열정, 직관력, 비판적 시각, 글쓰기 능력, 대화 능력 등 인문적 요소가 필요하다.
가. 통찰력 있는 분석
① 직관과 전략, 경영, 프레임워크 경험의 혼합을 통해 통찰력있는 분석을 수행
② 본인 회사 뿐 아니라, 전체 업계의 방향과 고객이 무엇을 중시하는지에 대한 이해가 필요
나. 인문학의 열풍
① 외부 환경적 측면에서 본 인문학 열풍의 이유
i. 컨버전스 -> 디버젼스
단순 세계화에서 복잡한 세계화로의 변화
ii. 생산 -> 서비스
비즈니스 중심이 제품생산에서 서비스로 이동
iii. 생산 -> 시장 창조
공급자 중심의 기술 경쟁에서 무형자산의 경쟁으로 변화
iv. 빅데이터 분석 기법의 이해와 분석 방법론 확대(X)
가. 디지털 환경의 전진과 더불어 실로 엄청난 “빅”데이터가 생성되고 있다
나. 빅데이터 분석은 선거결과에 결정적인 영향을 미칠 수 도 있다. 기업의 측면에서는 비용 절감, 시간 절약, 매출 증대, 고객서비스 향상, 신규 비즈니스 창출, 내부 의사결정 지원등에 있어 상당한 가치를 발휘하고 있다.
가. 과거
① Digitalization
② 아날로그 세상을 어떻게 효과적으로 디지털화하는지가 과거의 가치 창출 원천
나. 현재
① Connection
② 디지털화된 정보와 대상들은 서로 연결 시작
③ 연결을 더 효과적이고 효율적으로 제공하는지가 성공요인
다. 미래
① Agency
② 복잡한 연결을 어떻게 효과적이고 믿을 수 있게 관리하는지가 이슈
가. 데이터 사이언스의 한계
① 분석과정에서는 가정 등 인간의 해석이 개입되는 단계를 반드시 거친다
② 분석결과가 의미하는 바는 사람에 따라 전혀 다른 해석과 결론을 내릴 수 있다.
③ 아무리 정량적인 분석이라도 모든 분석은 가정에 근거한다는 사실이다.
나. 데이터 사이언스와 인문학
① 인문학을 이용하여 빅데이터와 데이터 사이언스가 데이터에 묻혀 있는 잠재력을 풀어내고, 새로운 기회를 찾고, 누구도 보지 못한 창조의 밑그림을 그릴 수 있는 힘을 발휘하게 될 것이다.
가. DBMS (Data Base Management System)
① DBMS 데이터베이스를 관리하여 응용 프로그램이 데이터베이스를 공유하며 사용할 수 있는 환경을 제공하는 소프트웨어
② 데이터베이스 관리시스템 종류
i. 관계형 DBMS
l 데이터를 컬럼(column)과 로우(row)를 이루는 하나 이상의 테이블로 정리하여 고유키가 각 로우를 식별한다.
ii. 객체지향 DBMS
l 정보를 “객체”형태로 표현하는 데이터베이스 모델
l 데이터 및 멀티미디어 데이터 등 복잡한 데이터 구조를 표현, 관리할 수 있는 데이터베이스 관리 시스템
iii. 네트워크 DBMS
l 레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 하는 데이터베이스 모델
iv. 계층형 DBMS
l 트리 구조를 기반으로 하는 계층 데이터베이스 모델
나. SQL (Structured Query Language)
① SQL
i. 데이터베이스의 하부 언어로, 단순한 질의 기능 뿐만 아니라 완전한 데이터의 정의와 조작 기능을 갖추고 있다.
ii. 영문 문장과 비슷한 구조
② SQL 집계함수
i. AVG, SUM, STDEV, MIN, MAX
l 수치형
ii. COUNT:
l 수치형, 문자형
l 어떠한 데이터의 타입에도 사용 가능
l 데이블의 트정 조건이 맞는 것의 개수를 반환
③ SELECT NAME, GENDER FROM CUSTOMERS WHERE AGE (BETWEEN) 20 AND 30
④ DML (Data Manipulation Language)
i. SELECT , INSERT, UPDATE, DELETE, CREATE(X)
⑤ DDL (Data Definition Language)
i. CREATE, ALTER, DROP, RENAME, TRUNCATE
⑥ DLC (Data Control Language)
i. GRANT, REVOKE
⑦ TCL (Transaction Control Language)
i. COMMIT, ROLLBACK, SAVEPOINT
가. 개인정보 비식별 기술
비식별 기술이란 데이터 셋에서 개인을 식별할 수 있는 요소를 전부 또는 일부를 삭제하거나 다른 값으로 대체하는 등의 방법으로 개인을 알아 볼 수 없도록 하는 기술을 일컫는다.
| 비식별기술 | 비식별기술 | 예시 |
| 데이터마스킹 | i. 데이터의 길이, 유형, 형식과 같은 속성을 유지한 채, 새롭고 읽기 쉬운 데이터를 익명으로 생성하는 기술 ii. 개인 정보 식별이 가능한 특정 데이터 값을 삭제 처리(X) |
홍길동,35세,서울 거주,한국대 재학 -->홍**,35세,서울 거주, **대학 재학 |
| 가명 처리 | i. 개인정보 주체의 이름을 다른 이름으로 변경하는 기술, 다른 값으로 대체할 시 일정한 규칙이 노출되지 않도록 주의해야 함 ii. 개인 식별이 가능한 데이터에 대하여 직접적으로 식별할 수 없는 다른 값으로 대체 |
홍길동,35세,서울 거주,한국대 재학 -->임꺽정,30대,서울 거주, 국내대학 재학 |
| 총계 처리 | i. 데이터의 총합 또는 평균값을 보임으로서 개별 데이터의 값을 보이지 않도록 함. 단, 특정 속성을 지닌 개인으로 구성된 단체의 속성 정보를 공개하는 것은 개인 정보를 공개하는 것과 마찬가지의 결과를 보임을 주의한다. | |
| 데이터값 삭제 | i. 데이터 공유, 개방 목적에 따라 데이터 셋에 구성된 값 중에 필요 없는 값 또는 개인 식별에 중요한 값을 삭제. | |
| 데이터 범주화 | i. 데이터의 값을 범주의 값으로 변형하여 값을 숨김 (홍길동->홍씨, 30~40세) ii. 단위 식별 정보를 해당 그룹의 대표 값으로 변환 |
|
| 난수화 | i. 사행활 침해를 막기 위해 개인 정보를 무작위 처리하는 등 데이터가 본래 목적 외에 가동되고 처리되는 것을 방지하는 기술 |
나. 무결성과 레이크
① 데이터 무결성(Data Integrity)
i. 데이터베이스 내의 데이터에 대한 정확한 일관성, 유효성, 신뢰성을 보장하기 위해 데이터 변경/수정 시 여러 가지 제한을 두어 데이터의 정확성을 보증하는 것
ii.무결설제한의 유형
- 개체 무결성(Entity integrity)
- 참조 무결성(Reference integrity)
- 범위 무결성(Domain integrity)
② 데이터 레이크 (Data Lake)
i. 수 많은 정보 속에서 의미 있는 내용을 찾기 위해 방식에 상관없이 데이터를 저장하는 시스템으로, 대용량의 정형 및 비정형 데이터를 저장할 뿐만 아니라 접근도 쉽게 할 수 있는 대규모 저장소
ii. 지난 몇 년간 여러 사일로 대신 하나의 데이터 소스를 추구하는 경향이 생겼다. 전사적으로 쉽게 인사이트를 공유하는 데 도움이 되기 때문이다. 다시 말해 별도로 정제되지 않은 자연스러운 상태의 아주 큰 데이터 세트인 (데이터 레이크)를 기업들이 구현하는 것은 2017년 새롭게 등장한 트렌드가 아니다. 그러나, 2017년 은 이를 적절히 관리해 운영하는 첫해가 될 전망이다.
iii. Apache Haddop, Teradata Integrated Big Data Platform 1700등과 같은 플랫폼으로 구성된 솔루션을 제공
④ 데이터 웨어하우스
i. 기업내의 의사 결정 지원 어플리케이션에 정보 기반을 제공하는 하나의 통합된 저장 공간
ii. 데이터의 주제 지향성, 데이터 통합, 데이터의 시계열성, 데이터의 비휘발성이라는 4가지 특성을 갖는다.
iii. 데이터웨어 하우스의 데이터들은 전사적 차원에서 일괄된 형식으로 정의된다
iv. 데이터 웨어하우스에서 관리되는 데이터들은 시간의 흐름에 따라 변화하는 값을 저장한다
v. 데이터 웨어하우스에서는 특정 주제에 따라 데이터들이 분류, 저장 관리된다.
vi. 기업의 의사 결정 과정을 지원하기 위한 주제 중심적으로 통합적이며 시간성을 가지는 비휘발성 데이터의 집합을 (데이터 웨어하우스, Data Warehouse)라고 한다.
vii. 데이터웨어하우스에서는 데이터의 지속적 갱신에 따른 무결성 유지가 무엇보다 중요하다(X)
가. 하둡(Hadoop)
① 여러 컴퓨터를 하나인 것처럼 묶어 대용량 데이터를 처리하는 기술
② 분산 파일 시스템을 통해 수 천대의 장비에 대용량 파일을 저장할 수 있는 기능
③ Map Reduce 로 HDFS에 저장된 대용량의 데이터를 대상으로 SQL 을 이용해 사용자 질의를 실시간 처리
④ 하둡의 부족한 기능을 서로 보완하는 ‘하둡 에코시스템’이 등장하여 다양한 솔루션을 제공한다.
나. Apache Spark
① 실시간 분산형 컴퓨팅 플랫폼
② 스칼라로 작성되어 있지만, 스칼라, 자바, R, 파이션 API 지원
③ In-Memory 방식으로 하둡에 비해 처리 속도가 빠르다.
다. Smart Factory
① 공장내 설비와 기계에 사물인터넷(IOT) 가 설치되어, 공정 데이터가 실시간으로 수집되고, 데이터 기반한 의사결정이 이뤄짐으로 생성성 극대화
라. Machine learning & Deep Learning
① 머신러닝은 인공지능 연구 분야 중 하나로, 인간의 학습 능력과 같은 기능을 컴퓨터에서 실행하고자 하는 기술 및 기법
② 딥러닝은 컴퓨터가 많은 데이터를 이용해 사람처럼 스스로 학습할 수 있게 하기 위하여 인공신경망(ANN, Artificial Neural Network)등의 기술을 기반하여 구축한 기계 학습 기술 중 하나이다.
③ 딥러닝은 다층구조 형태의 신경망을 바탕으로 하는 머신 러닝의 한 분야이다.
④ Deep learning은 대용량 데이터에서 의미있는 정보를 추출하여 의사결정에 활용하는 기술이다(X)
⑤ 데이터 마이닝(Data Mining)은 대용량 데이터에서 의미있는 정보를 추출하여 의사결정에 활용하는 기술이다
⑥ 딥러닝의 분석기법에는 ANN, CNN, RNN, LSTM, Autoencoder, SVM(X, 분류분석기법) 가 있다
⑦ 딥러닝 오픈소스에는 Caffe, Tensorflow, Theano, Anaconda(X) 가 있다.
가. 데이터양의 단위
| 단 위 | 데이터량 |
| 바이트(B) | |
| 킬로바이트(KB) | |
| 메가바이트(MB) | |
| 기가바이트(GB) | |
| 테라바이트(TB) | |
| 페타바이트(PB) | |
| 엑사바이트(EB) | |
| 제타바이트(ZB) | |
| 요타바이트(YB) |
나. B2B와 B2C
① B2B: 기업과 기업사이의 거래 기반의 비즈니스 모델
② B2C: 기업과 고객사의 거래 기반 비즈니스 모델
다. 블럭체인
① 거래정보를 하나의 덩어리로 보고 이를 차례로 연결한 거래 장부
② 거래에 참여하는 모든 사용자에게 거래 내역을 보내주며 거래 때마다 이를 대조해 위조를 방지
라. 사물 인터넷 (IOT, Internet of Things)
① 데이터화에 큰 영향을 미치는 기술이다.
② 인터넷 기반으로 모든 사물을 연겨해 사람과 사물, 사물과 사물 간의 정보를 상호 소통하는 지능형 기술 및 서비스이며, 사물에서 생성되는 Data를 활용한 분석을 통해 마케팅 등에 활용할 수 있다.
③ 사람의 개입 없이 사물간 통신하는 기술
마. 데이터의 유형
1.mysql 실행 : mariadb를 실행해도 mysql이 link되어 있어서 아무걸로나 실행해도 된다.
#mariadb -u root -p
#mysql -u root -p
비밀번호 변경
MariaDB [(none)]> ALTER USER 'root'@'localhost' IDENTIFIED BY '1234';
-현재 등록된 user가 뭐가 있는 지 확인하는 방법

- user 내용 보기
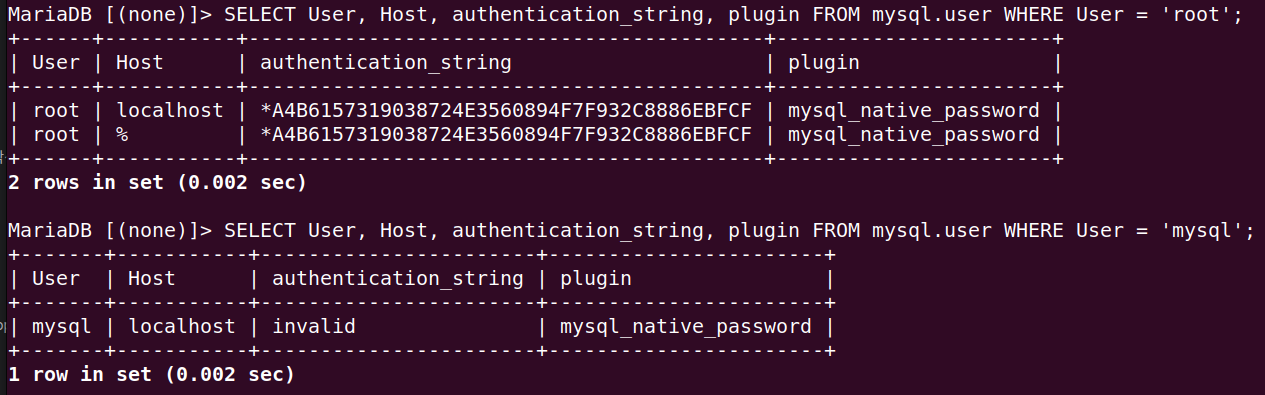
'root@모든PC'의 사용자가 접속되도록 하자. 그리고 비밀번호도 1234로 지정하자
MariaDB [(none)]> CREATE USER root@'%' IDENTIFIED BY '1234';
MariaDB [(none)]> GRANT ALL ON *.* root@'%' WITH GRANT OPTION;
MariaDB [(none)]> EXITMySQL 데이터베이스에 외부에서 접속할 수 있도록 하려면 몇 가지 단계를 따라야 합니다. 아래는 일반적인 방법을 안내하는 단계입니다.
**중요**: 외부 접속을 허용하는 것은 보안상 위험할 수 있으므로 신중하게 관리해야 합니다. 항상 필요한 보안 조치를 취하고, 권장되는 접근 방식을 따르세요.
1. **MySQL 서버 설정 확인 및 편집**:
MySQL 서버 설정 파일을 엽니다. 일반적으로 `my.cnf`나 `my.ini`로 불립니다.
2. **바인딩 주소 변경**:
기본적으로 MySQL 서버는 로컬 호스트에만 바인딩되어 있어 외부에서 접속할 수 없습니다. `bind-address` 항목을 주석 처리하거나 외부 IP 주소로 변경합니다.
```ini
# bind-address = 127.0.0.1
```
3. **사용자 계정 및 권한 설정**:
외부에서 접속할 수 있는 새로운 사용자 계정을 생성하거나, 기존의 사용자 계정을 수정합니다.
```sql
CREATE USER '사용자명'@'외부_IP' IDENTIFIED BY '비밀번호';
```
4. **접근 권한 부여**:
생성한 사용자에게 외부 접근 권한을 부여합니다. 필요한 데이터베이스나 테이블에 대한 권한도 설정합니다.
```sql
GRANT ALL PRIVILEGES ON '데이터베이스명'.* TO '사용자명'@'외부_IP';
FLUSH PRIVILEGES;
```
5. **방화벽 설정**:
MySQL 서버가 동작하는 포트(기본적으로 3306)가 방화벽에서 열려 있는지 확인하고, 필요하다면 해당 포트를 열어줍니다.
6. **MySQL 서버 재시작**:
설정 변경이 완료되면 MySQL 서버를 재시작하여 설정을 적용합니다.
이제 외부에서 지정한 IP 주소와 사용자명, 비밀번호를 사용하여 MySQL 데이터베이스에 접속할 수 있어야 합니다. 하지만, 보안을 위해서는 다음과 같은 추가적인 주의사항을 고려해야 합니다:
- **암호화**: 데이터베이스 접속 시 SSL을 사용하여 암호화된 연결을 설정하는 것이 좋습니다.
- **강력한 비밀번호**: 사용자 계정의 비밀번호는 강력하게 설정해야 하며, 주기적으로 변경되어야 합니다.
- **IP 제한**: 필요한 경우 특정 IP 주소만 접속을 허용하도록 설정할 수 있습니다.
- **백업 및 복원**: 데이터베이스의 백업과 복원 절차를 준비하여 데이터 손실을 방지합니다.
이러한 조치들은 데이터베이스의 보안을 강화하고 외부 접속으로 인한 잠재적인 위험을 최소화하는 데 도움이 됩니다.
2. SHOW: data base/table확인
| SHOW DATABASES; | 현재 만들어진 data base들을 보여줌 | |
| SHOW TABLES; | 현재 만들어진 table들을 보여줌 | |
| SHOW TABLE STATUS; | 명령어를 통한 테이블정보 조회 | |
| show columns from "테이블명"; | ||
| show full columns from "테이블명" ; |
3.USE : database로 이동
| USE "data base명"; | data base로 이동 | |
4. DROP : data base 삭제
| DROP DATABASE "data base명"; | data base 제거 | |
| DROP TABLE "table명"; | table 제거 |
참고: 외부 접속 방법
https://www.youtube.com/watch?v=kxIGx9_Hrl8
class란 객체를 생성하는 틀(template)로 data member라고도 불리는 속성과 동작을 수행하는 method로 구성된다.
클래스로부터 객체를 생성하는 것을 인스턴스화라고 하며, 생성된 인스턴스가 가지고 있는 속성과 메서드는 . 표기법을 사용해서 접근할 수 있다.
class A:
def methodA(self):
print("method...")
a=A() #인스턴스화
a.methodA() # 클래스 메서드 호출
상속은 클래스가 가지는 모든 속성과 메서드를 다른 클래스에 물려주는 기법이다. 이때 상속해주는 클래스를 부모 클래스 또는 슈퍼 클래스라고 하고, 상속 받는 클래스를 자식 클래스 또는 서브 클래스라고 한다.
class 자식 클래스(부모 클래스1, 부모 클래스2, ...):
pass
class A:
def methodA(self):
print("Calling A's methodA")
def method(self):
print("Calling A's method")
class B:
def methodB(self):
print("Calling B's methodB")
class C(A,B):
def methodC(self):
print("Calling C's methodC")
def method(self):
print("Calling C's overridden method")
super().method()
super().methodB()
c=C()
c.methodA()
c.methodB()
c.methodC()
c.method()
실행결과
Calling A's methodA
Calling B's methodB
Calling C's methodC
Calling C's overridden method
Calling A's method
Calling B's methodB클래스 내부에 존재하면서 메서드 밖에 정의된 변수를 클래스 변수라고 하며, 클래스의 모든 인스턴스는 클래스 변수를 공유한다. 반면에 인스턴스 변수는 메서드 내부에서 정의되며 변수명 앞에 self가 붙는데 해당 인스턴스에서만 사용할 수 있다.
class내부에 정의된 함수이다. class method의 첫번째 인수는 self로 정의해야 한다. 이 특별한 self 변수는 객체 자신을 의미한다.
class NasdaqStock:
"Class for NASDAQ stocks""" #doc string
count = 0 # class variable
def __init__(self,symbol,price):
"""Constructor for NasdaqStock""" # doc string
self.symbol = symbol #instance variable
self.price = price #instance variable
NasDaqStock.count +=1
print('Calling __init__({},{:.2f}) > count: {}'.format(self.symbol, self.price, NasdaqStock.count))
def __del__(self):
"Destructor for NasdaqStock""" # doc string
print('Calling __del__({})'.format(self))
class A:
def __init__(self):
self.result = 10
def methodA(self):
result =20
print("Calling A's methodA")
print("result{}".format(result))
def method(self):
print("Calling A's method")
self.methodA()
class B:
def __init__(self):
self.result = 20
def methodB(self):
print("Calling B's methodB")
class C(A, B):
def __init__(self):
self.result = 30
def methodC(self):
print("Calling C's methodC")
def method(self):
print("Calling C's overridden method")
super().method()
super().methodB()
c = C()
c.methodA()
c.methodB()
c.method()
print(c.result)수행 결과
Calling A's methodA
result20
Calling B's methodB
Calling C's overridden method
Calling A's method
Calling A's methodA
result20
Calling B's methodB
30self는 자기 자신을 의미하며
class 공용 변수를 사용할 경우 self.result와 같이 앞에 self를 붙여줘야 한다.
| [python]PyMYSQL (0) | 2022.08.07 |
|---|---|
| [python][graph]sine wave (0) | 2018.12.02 |
| python basic (0) | 2018.11.12 |
| python programming (0) | 2018.11.12 |
| [python][serial]serial port list (0) | 2018.11.12 |
0.개요
PyMYSQL은 DB(MySQL,mariaDB)같은 DB 프로그램을 사용할 수 있는 python library이다.
1.기본 정보
PyMYSQL에 대한 정보는 아래 홈페이지에 접속해서 보면 자세한 내용을 확인할 수 있다. 사용하기 위한 기본 요구사항과 기본 예제,문서, 소스코드를 확인할 수 있다.
PyMYSQL Homepage : https://github.com/PyMySQL/PyMySQL
기본 요구사항은 아래와 같다. 내 PC에 설치된 사항은 CPython 3.10.4이며 mariabd 10.6.7이 설치되어 있다.
#python3 -V
Python 3.10.4
#mariadb -V
mariadb Ver 15.1 Distrib 10.6.7-MariaDB, for debian-linux-gnu (x86_64) using EditLine wrapper
*maria db에 진입해서 version 정보를 읽는 방법과 실제 version정보를 확인할 수 있다.
이와 동일하게 python에서도 할 수 있는 걸 먼저 python code로 구현해 본다.
#mariadb -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 42
Server version: 10.6.7-MariaDB-2ubuntu1 Ubuntu 22.04
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select version();
+-------------------------+
| version() |
+-------------------------+
| 10.6.7-MariaDB-2ubuntu1 |
+-------------------------+
1 row in set (0.000 sec)
- mariadb version을 읽어오는 python code
import pymysql
connection = pymysql.connect(host='localhost', port=3306, db='db_name',
user='root', passwd='mypasswd', autocommit=True)
cursor = connection.cursor()
cursor.execute("SELECT VERSION();")
result = cursor.fetchone()
print ("MariaDB version : {}".format(result))
connection.close()위 코드 수행해서 읽어온 maria db version 정보이며 실제 maria db를 수행해서 읽어온 것과 동일한 것을 확인 할 수있다.
MariaDB version : ('10.6.7-MariaDB-2ubuntu1',)
잘되다가 아래 에러가 나면서 문제가 되는데 왜 발생하는 지 잘 모르겠다.
import pandas as pd
import yfinance as yf
import pandas_datareader as web
import pymysql
from sqlalchemy import create_engine
tickers = [
'SPY', # 미국 주식
'IEV', # 유럽 주식
'EWJ', # 일본 주식
'EEM', # 이머징 주식
'TLT', # 미국 장기채
'IEF', # 미국 중기채
'IYR', # 미국 리츠
'RWX', # 글로벌 리츠
'GLD', # 금
'DBC' # 상품
]
all_data = {}
for ticker in tickers:
#all_data[ticker] = web.DataReader(ticker, 'yahoo', start='1993-01-22')
all_data[ticker] = yf.download(ticker, start='1993-01-22')
prices = pd.DataFrame(
{tic: data['Adj Close']
for tic, data in all_data.items()})
engine = create_engine('mysql+pymysql://root:@127.0.0.1:3306/stock_db')
prices.to_sql(name='sample_etf', con=engine, index=True, if_exists='replace')
engine.dispose()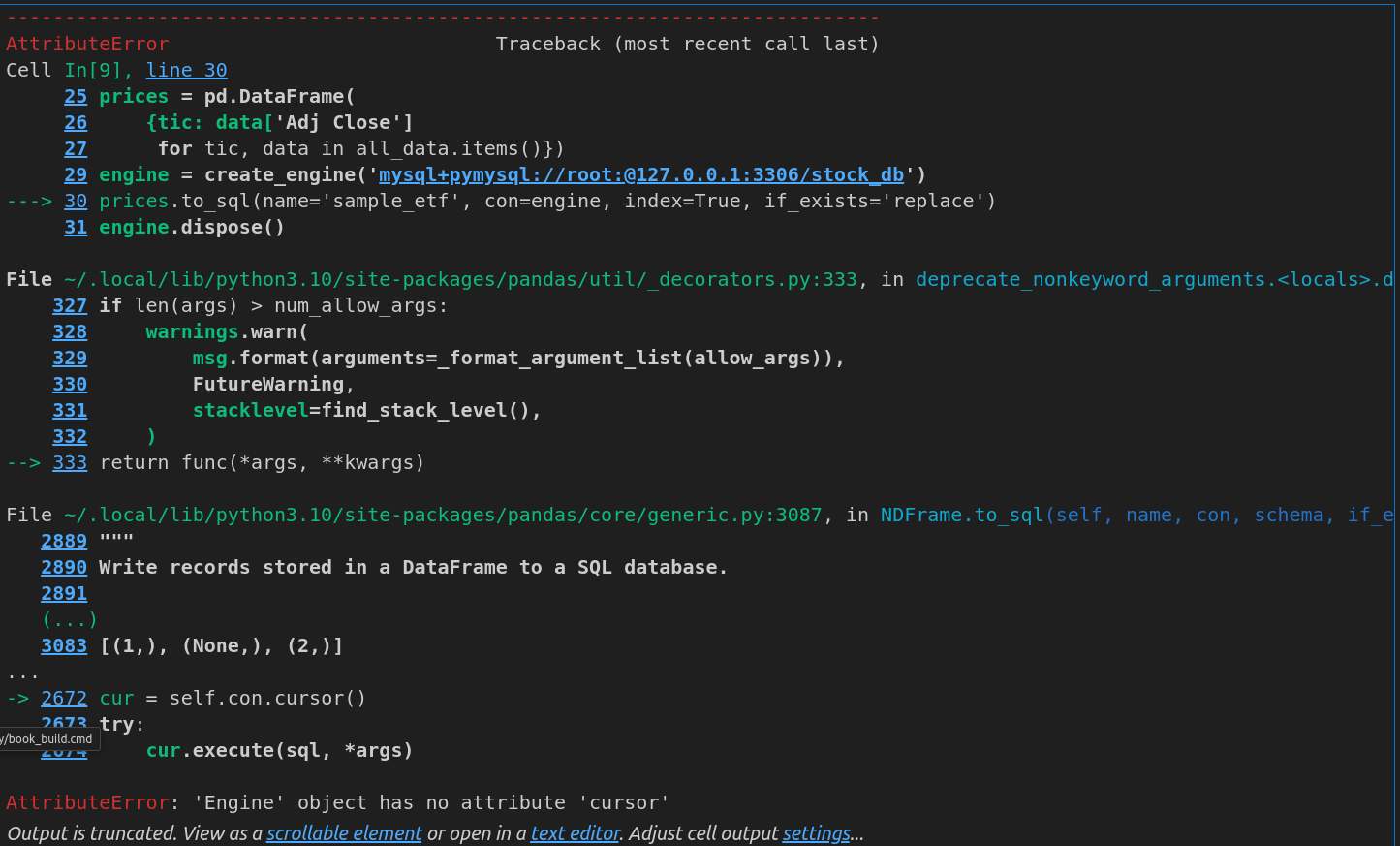
| [python]class (0) | 2022.08.11 |
|---|---|
| [python][graph]sine wave (0) | 2018.12.02 |
| python basic (0) | 2018.11.12 |
| python programming (0) | 2018.11.12 |
| [python][serial]serial port list (0) | 2018.11.12 |
https://www.acmicpc.net/problem/16928
16928번: 뱀과 사다리 게임
첫째 줄에 게임판에 있는 사다리의 수 N(1 ≤ N ≤ 15)과 뱀의 수 M(1 ≤ M ≤ 15)이 주어진다. 둘째 줄부터 N개의 줄에는 사다리의 정보를 의미하는 x, y (x < y)가 주어진다. x번 칸에 도착하면, y번 칸으
www.acmicpc.net
#include <iostream>
#include <queue>
using namespace std;
int dist[101];
int Next[101];
void Solve(){
dist[1]=0;
queue<int>q;
q.push(1);
while(!q.empty()) {
int x = q.front();
q.pop();
for (int i = 1; i <= 6; i++) {
int y=x+i;
if(y>100) continue;
y=Next[y];
if(dist[y] == -1){
dist[y]=dist[x]+1;
cout<<"i,x,y,dist[y];"<<i<<' '<<x<<' '<<y<<' '<<dist[y]<<endl;
q.push(y);
}
}
}
cout<<dist[100]<<endl;
}
void InputData(){
int n,m;
cin >> n>>m;
for(int i=1; i<=100; i++){
Next[i]=i;
dist[i]=-1;
}
for(int i=1; i<=n+m; i++){
int x,y;
cin>>x>>y;
Next[x]=y;
}
}
int main(){
InputData();
Solve();
return 0;
}i,x,y,dist[y];1 1 2 1
i,x,y,dist[y];2 1 3 1
i,x,y,dist[y];3 1 4 1
i,x,y,dist[y];4 1 5 1
i,x,y,dist[y];5 1 6 1
i,x,y,dist[y];6 1 7 1
i,x,y,dist[y];6 2 8 2
i,x,y,dist[y];6 3 9 2
i,x,y,dist[y];6 4 10 2
i,x,y,dist[y];6 5 11 2
i,x,y,dist[y];6 6 98 2
i,x,y,dist[y];6 7 13 2
i,x,y,dist[y];6 8 14 3
i,x,y,dist[y];6 9 15 3
i,x,y,dist[y];6 10 16 3
i,x,y,dist[y];6 11 17 3
i,x,y,dist[y];1 98 99 3
i,x,y,dist[y];2 98 100 3
i,x,y,dist[y];5 13 18 3
i,x,y,dist[y];6 13 19 3
i,x,y,dist[y];6 14 20 4
i,x,y,dist[y];6 15 21 4
i,x,y,dist[y];6 16 22 4
i,x,y,dist[y];6 17 23 4
i,x,y,dist[y];6 18 24 4
i,x,y,dist[y];6 19 25 4
i,x,y,dist[y];6 20 26 5
i,x,y,dist[y];6 21 27 5
i,x,y,dist[y];6 22 28 5
i,x,y,dist[y];6 23 29 5
i,x,y,dist[y];6 24 30 5
i,x,y,dist[y];6 25 31 5
i,x,y,dist[y];6 26 62 6
i,x,y,dist[y];6 27 33 6
i,x,y,dist[y];6 28 34 6
i,x,y,dist[y];6 29 35 6
i,x,y,dist[y];6 30 36 6
i,x,y,dist[y];6 31 37 6
i,x,y,dist[y];1 62 63 7
i,x,y,dist[y];2 62 64 7
i,x,y,dist[y];3 62 65 7
i,x,y,dist[y];4 62 66 7
i,x,y,dist[y];6 62 68 7
i,x,y,dist[y];5 33 38 7
i,x,y,dist[y];6 33 39 7
i,x,y,dist[y];6 34 40 7
i,x,y,dist[y];6 35 41 7
i,x,y,dist[y];6 37 43 7
i,x,y,dist[y];6 63 69 8
i,x,y,dist[y];6 64 70 8
i,x,y,dist[y];6 65 71 8
i,x,y,dist[y];6 66 72 8
i,x,y,dist[y];5 68 73 8
i,x,y,dist[y];6 68 74 8
i,x,y,dist[y];6 38 44 8
i,x,y,dist[y];6 39 45 8
i,x,y,dist[y];6 40 46 8
i,x,y,dist[y];6 41 47 8
i,x,y,dist[y];5 43 48 8
i,x,y,dist[y];6 70 76 9
i,x,y,dist[y];6 71 77 9
i,x,y,dist[y];6 72 78 9
i,x,y,dist[y];6 74 80 9
i,x,y,dist[y];6 44 50 9
i,x,y,dist[y];6 45 51 9
i,x,y,dist[y];6 46 52 9
i,x,y,dist[y];6 47 53 9
i,x,y,dist[y];6 48 54 9
i,x,y,dist[y];5 76 81 10
i,x,y,dist[y];6 76 82 10
i,x,y,dist[y];6 77 83 10
i,x,y,dist[y];6 78 84 10
i,x,y,dist[y];5 80 85 10
i,x,y,dist[y];6 80 86 10
i,x,y,dist[y];5 50 55 10
i,x,y,dist[y];6 50 56 10
i,x,y,dist[y];6 51 57 10
i,x,y,dist[y];6 52 58 10
i,x,y,dist[y];6 53 59 10
i,x,y,dist[y];6 54 60 10
i,x,y,dist[y];6 81 87 11
i,x,y,dist[y];6 82 88 11
i,x,y,dist[y];6 83 89 11
i,x,y,dist[y];6 84 90 11
i,x,y,dist[y];6 85 91 11
i,x,y,dist[y];6 86 92 11
i,x,y,dist[y];6 55 61 11
i,x,y,dist[y];6 88 94 12
i,x,y,dist[y];6 90 96 12
3| [C++][BFS]백준 2589 보물섬 (0) | 2022.04.11 |
|---|---|
| [C++][백준]1520 내리막길 (0) | 2022.04.10 |
| [C++][백준]14502 연구소 (0) | 2022.04.10 |
| [C++][백준]적록색약 (0) | 2022.04.10 |
| [c++][algoritm][baekjoon]7562 나이트의 이동 (0) | 2021.09.23 |
https://www.acmicpc.net/problem/1912
1912번: 연속합
첫째 줄에 정수 n(1 ≤ n ≤ 100,000)이 주어지고 둘째 줄에는 n개의 정수로 이루어진 수열이 주어진다. 수는 -1,000보다 크거나 같고, 1,000보다 작거나 같은 정수이다.
www.acmicpc.net
[풀이]
-다이나믹 프로그래밍으로 풀수 있다.
#include <iostream>
#define MAXN 100010
using namespace std;
int N;//입력 갯수
int A[MAXN];//입력 데이타 저장할 배열
int dp[MAXN];//다이나믹 프로그래밍 저장용 배열
void Solve(){
dp[1] = A[1];
int sol = dp[1];
for (int i = 2; i <= N; i++){
dp[i] = max(A[i], dp[i-1] + A[i]);
if(sol<dp[i]) sol= dp[i];
}
cout << sol << endl;
}
void InputData(){
cin >> N;
for(int i = 1; i <= N; i++) cin >> A[i];
}
int main(void){
InputData();
Solve();
return 0;
}
- dfs로 풀수 있다.
#include <iostream>
#include <algorithm>
using namespace std;
#define MAXN 100010
int N;
int D[MAXN];
int max_sum=(1<<31);
void dfs(int n, int sum){
if(n>N) return;
max_sum=max(max(max_sum,D[n]),sum);
if(D[n]>sum){
sum=0;
n--;
}
dfs(n+1,sum+D[n+1]);
}
void InputData(){
cin>>N;
for(int i=1; i<=N; i++)
cin>>D[i];
}
int main(){
InputData();
dfs(1,D[1]);
return 0;
}| [c++][baekjoon]1912 연속합 (0) | 2022.05.08 |
|---|---|
| [c++][algorithm][baekjoon]2839 설탕 배달 (0) | 2021.09.29 |
https://www.acmicpc.net/problem/1912
1912번: 연속합
첫째 줄에 정수 n(1 ≤ n ≤ 100,000)이 주어지고 둘째 줄에는 n개의 정수로 이루어진 수열이 주어진다. 수는 -1,000보다 크거나 같고, 1,000보다 작거나 같은 정수이다.
www.acmicpc.net
[풀이]
-다이나믹 프로그래밍으로 풀수 있다.
#include <iostream>
#define MAXN 100010
using namespace std;
int N;//입력 갯수
int A[MAXN];//입력 데이타 저장할 배열
int dp[MAXN];//다이나믹 프로그래밍 저장용 배열
void Solve(){
dp[1] = A[1];
int sol = dp[1];
for (int i = 2; i <= N; i++){
dp[i] = max(A[i], dp[i-1] + A[i]);
if(sol<dp[i]) sol= dp[i];
}
cout << sol << endl;
}
void InputData(){
cin >> N;
for(int i = 1; i <= N; i++) cin >> A[i];
}
int main(void){
InputData();
Solve();
return 0;
}
- dfs로 풀수 있다.
#include <iostream>
#include <algorithm>
using namespace std;
#define MAXN 100010
int N;
int D[MAXN];
int max_sum=(1<<31);
void dfs(int n, int sum){
if(n>N) return;
max_sum=max({max_sum,D[n],sum});
if(D[n]>sum){
sum=0;
n--;
}
dfs(n+1,sum+D[n+1]);
}
void InputData(){
cin>>N;
for(int i=1; i<=N; i++)
cin>>D[i];
}
int main(){
InputData();
dfs(1,D[1]);
cout<<max_sum<<endl;
return 0;
}| [c++][baekjoon]1912 연속합 (0) | 2022.05.09 |
|---|---|
| [c++][algorithm][baekjoon]2839 설탕 배달 (0) | 2021.09.29 |
https://www.acmicpc.net/problem/2589
[문제풀이]
1.BFS로 풀수 있다.
2.L:육지로 이동가능한곳, W:물로 이동할 수 없다
3.L만 찾아서 1개씩 큐에 저장후 이동할 수 있는 가장 먼 거리를 찾는 문제이다.
4.map정보가 같은 크기의 visited배열을 만들어서 방문 기록을 하고 매번 초기화 해줘야한다.
#include <iostream>
#include <queue>
#include <memory.h>
using namespace std;
#define MAXN (50)
int N, M;//세로, 가로
char map[MAXN+10][MAXN+10];//지도정보
int visited[MAXN+10][MAXN+10];//방문 표시
struct Q{
int y,x,t;
};
int count=0,ans=-1;
int BFS(int y, int x,int t){
queue<Q>q;
int dy[]={-1,1,0,0};//동서남북
int dx[]={0,0,-1,1};
//1.초기화
count=0;
q={};
//2.큐에 초기값 저장
q.push({y,x,t});
//3.반복문
while(!q.empty()){
Q cur=q.front();q.pop();
visited[y][x]=1;
for(int i=0; i<4; i++){
t=cur.t;
int ny=cur.y+dy[i];
int nx=cur.x+dx[i];
if((ny<0) || (ny>=N) || (nx<0) || (nx>=M) || map[ny][nx]!='L') continue;
if(visited[ny][nx]==0){
visited[ny][nx]=1;
q.push({ny,nx,t+1});
count=t+1;
if(ans<count) ans=count;//ans에 최대값 업데이트
}
}
}
return ans;
}
void Solve(){
for (int i=0; i<N; i++){
for (int j=0; j<M; j++){
if(map[i][j]=='L'){
ans=BFS(i,j,0);
memset(visited,false,sizeof(visited));
}
}
}
cout<<ans<<endl;
}
void InputData(){
cin>>N>>M;
for (int i=0; i<N; i++){
cin>>map[i];
}
}
int main(){
InputData();
Solve();
return 0;
}| [c++][백준]뱀과 사다리 (0) | 2022.05.16 |
|---|---|
| [C++][백준]1520 내리막길 (0) | 2022.04.10 |
| [C++][백준]14502 연구소 (0) | 2022.04.10 |
| [C++][백준]적록색약 (0) | 2022.04.10 |
| [c++][algoritm][baekjoon]7562 나이트의 이동 (0) | 2021.09.23 |
https://www.acmicpc.net/problem/1520
1520번: 내리막 길
첫째 줄에는 지도의 세로의 크기 M과 가로의 크기 N이 빈칸을 사이에 두고 주어진다. 이어 다음 M개 줄에 걸쳐 한 줄에 N개씩 위에서부터 차례로 각 지점의 높이가 빈 칸을 사이에 두고 주어진다.
www.acmicpc.net
[문제풀이]
1.dfs를 이용해서 푸는 문제이다.
2.최종 출력값은 visited[0][0]=3이 정답인데, visited[N-1][M-1]의 값이 정답으로 생각했는데, 의외인것 같다.
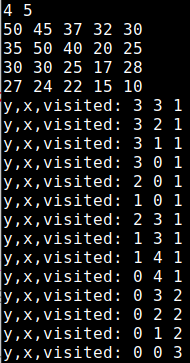
/*1520 내리막길 */
#include<iostream>
#include<memory.h>
using namespace std;
#define MAXN (int)5e2+10
int M,N;//행,열
int map[MAXN][MAXN];
int visited[MAXN][MAXN]={0,};//방문 표시
int dy[]={-1,1,0,0};//상하좌우
int dx[]={0,0,-1,1};
bool isInside(int a, int b){
return ( (a>=0) && (a<M) && (b>=0) && (b<N));
}
int DFS(int y, int x){
if(y==M-1 && x==N-1) return 1;
if(visited[y][x]!=-1) return visited[y][x];
visited[y][x]=0;
for(int i=0; i<4; i++){
int ny=y+dy[i];
int nx=x+dx[i];
if(isInside(ny,nx)){
if(map[ny][nx]<map[y][x])
visited[y][x]+=DFS(ny,nx);
}
}
return visited[y][x];
}
void InputData(){
cin>>M>>N;
for(int i=0; i<M; i++){
for(int j=0; j<N; j++){
cin>>map[i][j];
}
}
memset(visited,-1,sizeof(visited));
}
int main(){
InputData();
cout<<DFS(0,0);
return 0;
}| [c++][백준]뱀과 사다리 (0) | 2022.05.16 |
|---|---|
| [C++][BFS]백준 2589 보물섬 (0) | 2022.04.11 |
| [C++][백준]14502 연구소 (0) | 2022.04.10 |
| [C++][백준]적록색약 (0) | 2022.04.10 |
| [c++][algoritm][baekjoon]7562 나이트의 이동 (0) | 2021.09.23 |
https://www.acmicpc.net/problem/14502
[풀이과정]
1.바이러스 걸린 방의 위치 저장 해 둔다, 여기서는 vector를 사용했다.
배열을 사용해서 저장해도 되는데 사이즈를 따로 관리해야하는 번거로움이 있어서 vector를 이용했다.
BFS에서 사용할 queue에 저장해서 넘겨주면 될 것 같지만 그렇게 되면 BFS가 한번 돌고 나면 queue에서 사라지므로
변형되지 않는 곳을 만들어서 저장해 두어야 한다.
2.3가지 종류의 벽의 조합을 모두 만들어야 하므로 DFS를 사용해야 한다.
3.벽을 만든 후에는 vector에 저장된 바이러스가 퍼지는 는 맵을 완성한다.
4.바이러스가 모두 퍼진 후 전염되지 않은 방의 갯수를 센다.
5.2번부터 다시 반복해서 바이러스가 전염되지 않은 방 갯수 중 가장 큰 경우를 찾으면 된다.
#include<iostream>
#include<queue>
#include<vector>
using namespace std;
int N,M;//행,열
int map[8][8];
int tmp[8][8];//방문 표시
int dy[]={-1,1,0,0};//상하좌우
int dx[]={0,0,-1,1};
struct Q{
int y,x;
};
queue<Q>q;
vector<Q>v;
int sol=0;
bool isInside(int a, int b){
return ( (a>=0) && (a<N) && (b>=0) && (b<M));
}
int BFS(){
int count=0;
//1.큐 초기화
q={};
//2.큐에 초기값 입력
for(int i = 0; i < v.size(); i++)
q.push(v[i]);
//3.반복문
while(!q.empty()){
Q cur=q.front();q.pop();
for(int i=0; i<4; i++){
int ny=cur.y+dy[i];
int nx=cur.x+dx[i];
if(isInside(ny,nx) && tmp[ny][nx]==0){
tmp[ny][nx]=2;
q.push({ny,nx});
}
}
}
//4.return할 값
for(int i=0; i<N; i++){
for(int j=0; j<M; j++){
if(tmp[i][j]==0)
count++;
}
}
return count;
}
void copymap(){
for(int i=0; i<N; i++){
for(int j=0; j<M; j++){
tmp[i][j]=map[i][j];
}
}
}
void DFS(int x, int d){
if(d==3){
copymap();//기존 map을 훼손하면 안되므로 임시 map에 저장함
sol=max(sol,BFS());//감염되지 않은 방중 최대값으로 업데이트
return;
}
for(int i=x; i<N; i++){
for(int j=0; j<M; j++){
if(map[i][j]==0){
map[i][j]=1;
DFS(i,d+1);
map[i][j]=0;
}
}
}
}
void Solve(){
DFS(0,0);//맵에서 벽을 세울수 있는 경우를 DFS를 이용해서 조합으로 만듬
cout<<sol<<endl;//오염되지 않은 방중 가장 큰값
}
void InputData(){
cin>>N>>M;
for(int i=0; i<N; i++){
for(int j=0; j<M; j++){
cin>>map[i][j];
if(map[i][j]==2){
v.push_back({i,j});//바이러스 걸린 방을 따로 저장해 두어야한다.
}
}
}
}
int main(){
InputData();
Solve();
return 0;
}| [C++][BFS]백준 2589 보물섬 (0) | 2022.04.11 |
|---|---|
| [C++][백준]1520 내리막길 (0) | 2022.04.10 |
| [C++][백준]적록색약 (0) | 2022.04.10 |
| [c++][algoritm][baekjoon]7562 나이트의 이동 (0) | 2021.09.23 |
| [c++][algorithm][baekjoon][7569]토마토 (0) | 2021.08.29 |
https://www.acmicpc.net/problem/10026
[풀이과정]
1.R,G,B 각 글자에 대해서 FloodFill을 이용해서 글자가 상하좌우에 연결된 부분을 찾는다.
2.전체 맵을 각 글자의 묶음들이 있는 걸 count해서 R,G,B 각 글자에 대해서 숫자를 count한다.
3.적록 색맹을 경우는 R를 G로 변경하는 작업을 해 준다.
4.1번 부터 동일한 과정으로 R,G에 대한 count를 해주면 된다.
/*백준 10026 적록색약*/
#include<iostream>
#include<memory.h>
using namespace std;
#define MAXN (int)1e2+10
char map[MAXN][MAXN];
int visited[MAXN][MAXN];//방문 표시
int N;//행,열
int dy[]={-1,1,0,0};
int dx[]={0,0,-1,1};
bool isInside(int a, int b){
return ( (a>=0) && (a<N) && (b>=0) && (b<N));
}
bool DFS(int y, int x, char c){
if(isInside(y,x) && visited[y][x]==0 && map[y][x]==c){
visited[y][x]=1;
for(int i=0; i<4; i++){
DFS(y+dy[i],x+dx[i],c);
//cout<<y+dy[i]<<' '<<x+dx[i]<<endl;
}
return true;
}else{
return false;
}
}
int Calc(int c){
int cnt=0;
for(int i=0; i<N; i++){
for(int j=0; j<N; j++){
if(map[i][j]==c)
cnt+=DFS(i,j,c);
}
}
return cnt;
}
void remap(){
for(int i=0; i<N; i++){
for(int j=0; j<N; j++){
if(map[i][j]=='R')
map[i][j]='G';
}
}
}
void Solve(){
int cnt1=0,cnt2=0;
cnt1+=Calc('R');
cnt1+=Calc('G');
cnt1+=Calc('B');
memset(visited,false,sizeof(visited));
remap();
cnt2+=Calc('G');
cnt2+=Calc('B');
cout<<cnt1<<' '<<cnt2<<endl;
}
void InputData(){
cin>>N;
for(int i=0; i<N; i++){
cin>>map[i];
}
}
int main(){
InputData();
Solve();
return 0;
}| [C++][백준]1520 내리막길 (0) | 2022.04.10 |
|---|---|
| [C++][백준]14502 연구소 (0) | 2022.04.10 |
| [c++][algoritm][baekjoon]7562 나이트의 이동 (0) | 2021.09.23 |
| [c++][algorithm][baekjoon][7569]토마토 (0) | 2021.08.29 |
| [c++][algorithm][baekjoon][11724]연결 요소의 개수 (0) | 2021.08.27 |
수열 A가 주어졌을 때, 가장 긴 증가하는 부분 수열을 구하는 프로그램을 작성하시오.
예를 들어, 수열 A = {10, 20, 10, 30, 20, 50} 인 경우에 가장 긴 증가하는 부분 수열은 A = {10, 20, 10, 30, 20, 50} 이고, 길이는 4이다.
첫째 줄에 수열 A의 크기 N (1 ≤ N ≤ 1,000,000)이 주어진다.
둘째 줄에는 수열 A를 이루고 있는 Ai가 주어진다. (1 ≤ Ai ≤ 1,000,000)
첫째 줄에 수열 A의 가장 긴 증가하는 부분 수열의 길이를 출력한다.
예제 입력 1
6
10 20 10 30 20 50
예제 출력 1
4
8
10 20 30 5 10 20 30 40
정답: 5
반례 추가
10
4 7 10 3 1 8 7 2 5 7
Answer: 4
7
7 9 10 8 2 3 7
Answer: 3
10
7 10 8 10 1 2 9 9 1 10
Answer: 4
9
2 8 3 10 5 1 5 2 3
Answer: 3
10
10 6 5 9 10 9 3 4 7 1
Answer: 3
10
5 8 10 3 9 1 5 8 5 6
Answer: 3
9
3 2 8 2 10 1 2 2 3
Answer: 3
10
3 8 10 1 5 7 9 8 9 6
Answer: 5
7
4 3 4 9 1 3 7
Answer: 3
10
8 6 8 9 5 1 4 4 6 3
Answer: 3
/*[12015]가장 긴 증가하는 부분 수열2*/
#include <bits/stdc++.h>
using namespace std;
#define MAXN ((int)1e6+10)
int N;
int A[MAXN];
vector<int> v;
auto it = v.begin();
void InputData(){
cin >> N;
for(int i=0; i<N; i++){
cin >> A[i];
}
}
void Solve(){
v.push_back(A[0]);
for(int i=1; i<N; i++){
if(v.back() < A[i] ) v.push_back(A[i]);
else {
it = v.begin();
it = lower_bound(v.begin(), v.end(), A[i]);
*it = A[i];
}
}
cout << v.size() << endl;
}
int main(){
InputData();
Solve();
return 0;
}
/*[12015]가장 긴 증가하는 부분 수열2*/| [c++][algorithm][baekjoon]1300번 K번째 수 (0) | 2021.12.09 |
|---|---|
| [c++][algorithm][baekjoon]2110번 공유기 설치 (0) | 2021.12.09 |
| [c++][algorithm][baekjoon]2805 나무자르기 (0) | 2021.12.09 |
| [c++][algorithm]baekjoon 10816 숫자 카드2 (0) | 2021.07.06 |
| [c++][algorithm][baekjoon]1920 수 찾기 (0) | 2021.07.06 |
세준이는 크기가 N×N인 배열 A를 만들었다. 배열에 들어있는 수 A[i][j] = i×j 이다. 이 수를 일차원 배열 B에 넣으면 B의 크기는 N×N이 된다. B를 오름차순 정렬했을 때, B[k]를 구해보자.
배열 A와 B의 인덱스는 1부터 시작한다.
첫째 줄에 배열의 크기 N이 주어진다. N은 105보다 작거나 같은 자연수이다. 둘째 줄에 k가 주어진다. k는 min(109, N2)보다 작거나 같은 자연수이다.
B[k]를 출력한다.
예제 입력 1
3
7
예제 출력 1
6
3
7
i: 1 lo:1 hi : 7 mid: 4 tmp: 3
i: 2 lo:1 hi : 7 mid: 4 tmp: 5
i: 3 lo:1 hi : 7 mid: 4 tmp: 6
i: 1 lo:5 hi : 7 mid: 6 tmp: 3
i: 2 lo:5 hi : 7 mid: 6 tmp: 6
i: 3 lo:5 hi : 7 mid: 6 tmp: 8
i: 1 lo:5 hi : 5 mid: 5 tmp: 3
i: 2 lo:5 hi : 5 mid: 5 tmp: 5
i: 3 lo:5 hi : 5 mid: 5 tmp: 6
6
| [c++][algorithm][baekjoon]12015번 가장 긴 증가하는 부분 수열2 (0) | 2021.12.09 |
|---|---|
| [c++][algorithm][baekjoon]2110번 공유기 설치 (0) | 2021.12.09 |
| [c++][algorithm][baekjoon]2805 나무자르기 (0) | 2021.12.09 |
| [c++][algorithm]baekjoon 10816 숫자 카드2 (0) | 2021.07.06 |
| [c++][algorithm][baekjoon]1920 수 찾기 (0) | 2021.07.06 |
도현이의 집 N개가 수직선 위에 있다. 각각의 집의 좌표는 x1, ..., xN이고, 집 여러개가 같은 좌표를 가지는 일은 없다.
도현이는 언제 어디서나 와이파이를 즐기기 위해서 집에 공유기 C개를 설치하려고 한다. 최대한 많은 곳에서 와이파이를 사용하려고 하기 때문에, 한 집에는 공유기를 하나만 설치할 수 있고, 가장 인접한 두 공유기 사이의 거리를 가능한 크게 하여 설치하려고 한다.
C개의 공유기를 N개의 집에 적당히 설치해서, 가장 인접한 두 공유기 사이의 거리를 최대로 하는 프로그램을 작성하시오.
첫째 줄에 집의 개수 N (2 ≤ N ≤ 200,000)과 공유기의 개수 C (2 ≤ C ≤ N)이 하나 이상의 빈 칸을 사이에 두고 주어진다. 둘째 줄부터 N개의 줄에는 집의 좌표를 나타내는 xi (0 ≤ xi ≤ 1,000,000,000)가 한 줄에 하나씩 주어진다.
첫째 줄에 가장 인접한 두 공유기 사이의 최대 거리를 출력한다.
예제입력1
5 3
1
2
8
4
9
예제출력1
3
N : 집의 개수
C : 공유기 개수
이후 집의 좌표
N : 3, C: 3
집의 좌표를 먼저 오름차순으로 정렬한다.
1 2 4 8 9
5 3
1
2
8
4
9
i: 1 X[i] : 2 lo:1 hi : 8 mid: 4 start: 1 cnt :1
i: 2 X[i] : 4 lo:1 hi : 8 mid: 4 start: 1 cnt :1
i: 3 X[i] : 8 lo:1 hi : 8 mid: 4 start: 8 cnt :2
i: 4 X[i] : 9 lo:1 hi : 8 mid: 4 start: 8 cnt :2
i: 1 X[i] : 2 lo:1 hi : 3 mid: 2 start: 1 cnt :1
i: 2 X[i] : 4 lo:1 hi : 3 mid: 2 start: 4 cnt :2
i: 3 X[i] : 8 lo:1 hi : 3 mid: 2 start: 8 cnt :3
i: 4 X[i] : 9 lo:1 hi : 3 mid: 2 start: 8 cnt :3
i: 1 X[i] : 2 lo:3 hi : 3 mid: 3 start: 1 cnt :1
i: 2 X[i] : 4 lo:3 hi : 3 mid: 3 start: 4 cnt :2
i: 3 X[i] : 8 lo:3 hi : 3 mid: 3 start: 8 cnt :3
i: 4 X[i] : 9 lo:3 hi : 3 mid: 3 start: 8 cnt :3
3
/*[2110]공유기 설치*/
#include <bits/stdc++.h>
using namespace std;
#define MAXN ((int)2e5+10)
int N,C; //집의 개수, 공유기개수
int X[MAXN];
long long M;
void InputData(){
cin >> N >> C;
for(int i =0; i<N; i++){
cin >> X[i];
}
}
void Solve(){
int lo, hi, mid;
long long sum;
sort(X,X+N);
lo = 1;
hi = X[N-1] - X[0];
int d = 0;
int ans = 0;
while(lo <= hi){
mid=(lo+hi)/2;
int start = X[0];
int cnt = 1;
for(int i=1; i<N; i++){
d = X[i] - start;
if(mid <= d){
++cnt;
start = X[i];
}
cout << "i: " << i << " X[i] : " << X[i] << " lo:" << lo << " hi : " << hi << " mid: " << mid << " start: " << start << " cnt :" << cnt << endl;
}
if( cnt >= C){
ans = mid;
lo = mid + 1;
}else{
hi = mid - 1;
}
}
cout << ans << endl;
}
int main(){
InputData();
Solve();
return 0;
}
/*[2110]공유기 설치*/| [c++][algorithm][baekjoon]12015번 가장 긴 증가하는 부분 수열2 (0) | 2021.12.09 |
|---|---|
| [c++][algorithm][baekjoon]1300번 K번째 수 (0) | 2021.12.09 |
| [c++][algorithm][baekjoon]2805 나무자르기 (0) | 2021.12.09 |
| [c++][algorithm]baekjoon 10816 숫자 카드2 (0) | 2021.07.06 |
| [c++][algorithm][baekjoon]1920 수 찾기 (0) | 2021.07.06 |
상근이는 나무 M미터가 필요하다. 근처에 나무를 구입할 곳이 모두 망해버렸기 때문에, 정부에 벌목 허가를 요청했다. 정부는 상근이네 집 근처의 나무 한 줄에 대한 벌목 허가를 내주었고, 상근이는 새로 구입한 목재절단기를 이용해서 나무를 구할것이다.
목재절단기는 다음과 같이 동작한다. 먼저, 상근이는 절단기에 높이 H를 지정해야 한다. 높이를 지정하면 톱날이 땅으로부터 H미터 위로 올라간다. 그 다음, 한 줄에 연속해있는 나무를 모두 절단해버린다. 따라서, 높이가 H보다 큰 나무는 H 위의 부분이 잘릴 것이고, 낮은 나무는 잘리지 않을 것이다. 예를 들어, 한 줄에 연속해있는 나무의 높이가 20, 15, 10, 17이라고 하자. 상근이가 높이를 15로 지정했다면, 나무를 자른 뒤의 높이는 15, 15, 10, 15가 될 것이고, 상근이는 길이가 5인 나무와 2인 나무를 들고 집에 갈 것이다. (총 7미터를 집에 들고 간다) 절단기에 설정할 수 있는 높이는 양의 정수 또는 0이다.
상근이는 환경에 매우 관심이 많기 때문에, 나무를 필요한 만큼만 집으로 가져가려고 한다. 이때, 적어도 M미터의 나무를 집에 가져가기 위해서 절단기에 설정할 수 있는 높이의 최댓값을 구하는 프로그램을 작성하시오.
첫째 줄에 나무의 수 N과 상근이가 집으로 가져가려고 하는 나무의 길이 M이 주어진다. (1 ≤ N ≤ 1,000,000, 1 ≤ M ≤ 2,000,000,000)
둘째 줄에는 나무의 높이가 주어진다. 나무의 높이의 합은 항상 M보다 크거나 같기 때문에, 상근이는 집에 필요한 나무를 항상 가져갈 수 있다. 높이는 1,000,000,000보다 작거나 같은 양의 정수 또는 0이다.
적어도 M미터의 나무를 집에 가져가기 위해서 절단기에 설정할 수 있는 높이의 최댓값을 출력한다.
4 7
20 15 10 17
출력 : 15
5 20
4 42 40 26 46
출력:36
2 11
10 10
출력 : 4
3 1
1 2 2
출력 : 1
4 10
1 4 5 7
출력:2
5 2000000000
900000000 900000000 900000000 900000000 900000000
출력: 500000000
1 1000000000
1000000000
출력: 0
1 1
1000000000
출력: 999999999
6 12
19 9 18 20 17 8
출력: 15
5 14
4 22 10 16 36
출력: 22나무수 N이 1,000,000개 이어서 이진 탐색으로 해서 찾아야 시간 초과 발생하지 않고 해결이 된다고 추측할 수 있다.
이진탐색색을 하기 위해서는 찾고자 하는 데이타를 오름차순 정렬을 해야 한다.
여기서 데이타는 나무 높이 데이타인 A를 정령해야 한다.
lo,hi값을 선정해야하는데, sorting후 제일 작은 값과 제일 큰 값으로 선정하면 된다.
/*[2805]나무자르기*/
#include <bits/stdc++.h>
using namespace std;
#define MAXN ((int)1e6+10)
int N;
int A[MAXN +10];
long long M;
void Solve(){
int lo, hi, mid,sol=0;
long long sum;
sort(A,A+N);
lo = 1;
hi = A[N-1];
while(lo <= hi){
sum=0;
mid=(lo+hi)/2;
for(int i=0; i<N; i++){
if(A[i] > mid) sum += (A[i] - mid);
}
if(sum >= M){
sol=mid;
lo=mid+1;
}else{
hi = mid-1;
}
}
cout << sol << endl;
}
void InputData(){
cin >> N >> M;
for(int i =0; i<N; i++){
cin >> A[i];
}
}
int main(){
InputData();
Solve();
return 0;
}
/*[2805]나무자르기*/| [c++][algorithm][baekjoon]12015번 가장 긴 증가하는 부분 수열2 (0) | 2021.12.09 |
|---|---|
| [c++][algorithm][baekjoon]1300번 K번째 수 (0) | 2021.12.09 |
| [c++][algorithm][baekjoon]2110번 공유기 설치 (0) | 2021.12.09 |
| [c++][algorithm]baekjoon 10816 숫자 카드2 (0) | 2021.07.06 |
| [c++][algorithm][baekjoon]1920 수 찾기 (0) | 2021.07.06 |
예제 입력 1
5
예제 출력 1
*
**
***
****
*****#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=1; i<=N; i++){
for(int j=1; j<=i; j++){
printf("*");
}
cout << endl;
}
return 0;
}
예제 입력 1
5
예제 출력 1
*
**
***
****
*****#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=1; i<=N; i++){
for(int k=1; k<=N-i; k++){
cout << " ";
}
for(int j=1; j<=i; j++){
cout << "*";
}
cout << endl;
}
return 0;
}예제 입력 1
5
예제 출력 1
*****
****
***
**
*#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=0; i<N; i++){
for(int j=0; j<N-i; j++){
cout << "*";
}
cout << endl;
}
return 0;
}예제 입력 1
5
예제 출력 1
*****
****
***
**
*#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=0; i<N; i++){
for(int k=0; k<i; k++){
cout << " ";
}
for(int j=0; j<N-i; j++){
cout << "*";
}
cout << endl;
}
return 0;
}예제 입력 1
5
예제 출력 1
*
***
*****
*******
*********
#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=1; i<=N; i++){
for(int k=1; k<=N-i; k++){
cout << " ";
}
for(int j=1; j<=2*i-1; j++){
cout << "*";
}
cout << endl;
}
return 0;
}ㅗ
예제 입력 1
5
예제 출력 1
*********
*******
*****
***
*#include <bits/stdc++.h>
using namespace std;
int main()
{
int N;
cin >> N;
for(int i=0; i<N; i++){
for(int k=0; k<i; k++){
cout << " ";
}
for(int j=0; j<2*(N-i)-1; j++){
cout << "*";
}
cout << endl;
}
return 0;
}예제 입력 1
5
예제 출력 1
*
***
*****
*******
*********
*******
*****
***
*| [c++]baekjoon 2477 참외밭 (0) | 2021.06.05 |
|---|---|
| [c++]baekjoon 2166 다각형의 면적 (0) | 2021.06.05 |
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 45보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
풀이
아래 코드 입력 시 시간 초과 발생한다.
#include <bits/stdc++.h>
using namespace std;
int fibo(int a)
{
if( a == 0)
return 0;
else if(a ==1)
return 1;
else
return (fibo(a-1) + fibo(a-2));
}
int main()
{
int repeat;
cin >> repeat;
cout << fibo(repeat);
return 0;
}아래와 같이 dynamic programming방식으로 풀어서 시간초과를 없앴다.
/*[baekjoon][2747] 피보나치 수*/
#include <bits/stdc++.h>
using namespace std;
int d[50];
int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2747] 피보나치 수*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 90보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
/*[baekjoon][2748] 피보나치 수 2*/
#include <bits/stdc++.h>
using namespace std;
long long int d[100];
long long int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2748] 피보나치 수 2*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 1,000,000,000,000,000,000보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 1,000,000으로 나눈 나머지를 출력한다.
1000
228875
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
|---|---|
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
| [c++][algorithm]백준 2839 설탕배달 (0) | 2021.05.09 |
| [c++]baekjoon 1712 손익분기점 (0) | 2021.05.04 |
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 45보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
풀이
아래 코드 입력 시 시간 초과 발생한다.
#include <bits/stdc++.h>
using namespace std;
int fibo(int a)
{
if( a == 0)
return 0;
else if(a ==1)
return 1;
else
return (fibo(a-1) + fibo(a-2));
}
int main()
{
int repeat;
cin >> repeat;
cout << fibo(repeat);
return 0;
}아래와 같이 dynamic programming방식으로 풀어서 시간초과를 없앴다.
/*[baekjoon][2747] 피보나치 수*/
#include <bits/stdc++.h>
using namespace std;
int d[50];
int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2747] 피보나치 수*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 90보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
/*[baekjoon][2748] 피보나치 수 2*/
#include <bits/stdc++.h>
using namespace std;
long long int d[100];
long long int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2748] 피보나치 수 2*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 1,000,000,000,000,000,000보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 1,000,000으로 나눈 나머지를 출력한다.
1000
228875
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
|---|---|
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
| [c++][algorithm]백준 2839 설탕배달 (0) | 2021.05.09 |
| [c++]baekjoon 1712 손익분기점 (0) | 2021.05.04 |
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 45보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
풀이
아래 코드 입력 시 시간 초과 발생한다.
#include <bits/stdc++.h>
using namespace std;
int fibo(int a)
{
if( a == 0)
return 0;
else if(a ==1)
return 1;
else
return (fibo(a-1) + fibo(a-2));
}
int main()
{
int repeat;
cin >> repeat;
cout << fibo(repeat);
return 0;
}아래와 같이 dynamic programming방식으로 풀어서 시간초과를 없앴다.
/*[baekjoon][2747] 피보나치 수*/
#include <bits/stdc++.h>
using namespace std;
int d[50];
int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2747] 피보나치 수*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 90보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 출력한다.
10
55
/*[baekjoon][2748] 피보나치 수 2*/
#include <bits/stdc++.h>
using namespace std;
long long int d[100];
long long int fibonacci(int n)
{
if( n == 0) return 0;
else if(n ==1) return 1;
else if(d[n] != 0) return d[n];
return d[n]=(fibonacci(n-1) + fibonacci(n-2));
}
int main()
{
int n;
cin >> n;
cout << fibonacci(n);
return 0;
}
/*[baekjoon][2748] 피보나치 수 2*/
피보나치 수는 0과 1로 시작한다. 0번째 피보나치 수는 0이고, 1번째 피보나치 수는 1이다. 그 다음 2번째 부터는 바로 앞 두 피보나치 수의 합이 된다.
이를 식으로 써보면 Fn = Fn-1 + Fn-2 (n ≥ 2)가 된다.
n=17일때 까지 피보나치 수를 써보면 다음과 같다.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597
n이 주어졌을 때, n번째 피보나치 수를 구하는 프로그램을 작성하시오.
첫째 줄에 n이 주어진다. n은 1,000,000,000,000,000,000보다 작거나 같은 자연수이다.
첫째 줄에 n번째 피보나치 수를 1,000,000으로 나눈 나머지를 출력한다.
1000
228875
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
|---|---|
| [c++][algorithm][baekjoon][2747] 피보나치 수 (0) | 2021.10.07 |
| [c++][algorithm]백준 2839 설탕배달 (0) | 2021.05.09 |
| [c++]baekjoon 1712 손익분기점 (0) | 2021.05.04 |